پنج مقاله که برای شروع یادگیری عمیق باید خواند
- گوگل
- ام ای تی
- شبکه عصبی
تاریخچه رقابت ImageNet: قدرت شبکه های کانولوشن در سال 1989 ، هنگامی که یان لیکون و همکارانش ارقام دست نویس را با دقت 95 درصد طبقه بندی کردند نشان داده شد. سال 2012 اولین سالی بود که شبکه های عصبی برجسته تر شدند .
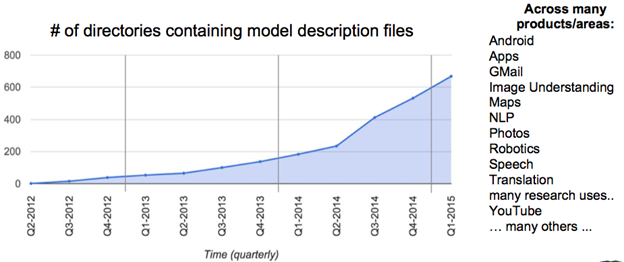
در این سال الکس کریژوسکیو جفری هینتون از آن برای پیروز شدن در رقابت ImageNet استفاده کردند. کاهش خطا از 26درصد به 15 درصد یک پیشرفت عظیم در آن زمان بود . از آن زمان به بعد بزرگترین شرکت های بزرگ دنیا اعم از فیس بوک،گوگل و … از یادگیری عمیق در اکثر سرویس های خود استفاده کردند. به عنوان مثال شرکت فیس بوک از شبکه های عصبی عمیق برای برچسب گذاری عکس به صورت خودکار ، شرکت گول برای جستجوی عکس و آمازون برای پیشنهاد کالا به کاربران استفاده میکنند. در شکل ذیل افزایش یادگیری عمیق در سرویس های گوگل تا سال 2015 نمایش داده شده است .
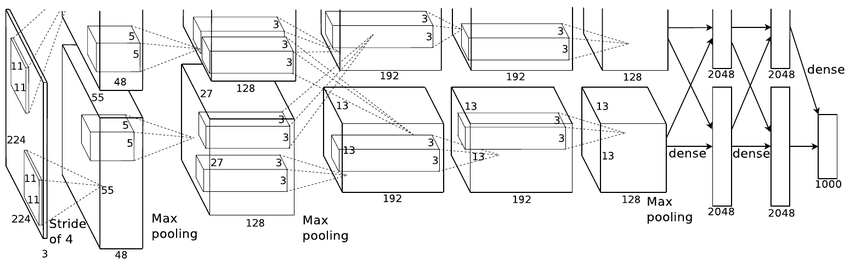
معماری الکس نت
اولین شبکه عصبی کانولوشن که در چالشILSVRC-2012 اعمال شد AlexNetبود ، این معماری داده های پایگاه داده ImageNet که در 1000 گروه طبقه بندی شده بودند را با خطای 15 درصد طبقه بندی کرد. این معماری شامل 5 لایه کانولوشن ادغام شده با لایه های max-poolingو سه لایه تماما متصل است.
نکات اصلی:
👌این معماری توسط دادهای پایگاه داده ImageNet آموزش داده شد این دیتا بیس شامل 15 میلیون عکس در 22 هزار گروه است.
👌از تابع فعال ساز ReLU استفاده شد (برای کاهش زمان آموزش)این تابع چندین برابر از توابع فعار ساز tanhو sigmoidسریعتر است
👌از تکنیک data augmentationاستفاده شد.شامل: image translations، horizontal reflectionsو patch extractions
👌پیاده سازی لایه Droupout برای مبارزه با بیش برارزش شدن نمونه های آموزشی
👌از mini-batch stochastic gradient descent با مقادیر مشخص momentum و weight decay برای آموزش شبکه استفاده شد
👌این معماری توسط دو کارت گرافیک GTX 580برای 5 تا 6 روز آموزش داده شد. این اولین بار بود که یک مدل خیلی خوب بر روی این پایگاه داده عمل کرد و امروزه هنوز از تکنیک هایی مثل data augmentation و dropout به صورت وسیع استفاده میشود.
معماری ZF Net
سال 2013 بعد از ارایه معماریAlexNet تعدادی زیادی مدل برای رقابت ILSVRC2013 ارایه شد. برنده رقابت این سال معماری بود که توسط Zeiler و همکاران ارایه شد . نام این معماری ZF Net بود که به خطای 11.2 درصد دست پیدا کرد. این معماری در واقع بیشتر مدل تنظیم شده معماری AlexNet بود اما تعدادی ایده اساسی جهت افزایش کارایی معرفی شد.دلیل دیگری که این مقاله را به یک مقاله عالی تبدیل کرد باز کردن پنجره های جدید به سوی هر چه بهتر درک کردن فرآیند یادگیری شبکه های کانولوشن بود . نویسنده این مقاله زمانی زیادی را صرف چگونگی عملکرد شبکه های عصبی کانولوشن ، چگونگی نمایش فیلتر ها و ورزن ها کرد. این ویژوال سازی باعت شد تا درک بهتری از درون این شبکه ها ایجاد شود مواردی از قبیل اینکه نورن ها در هر لایه چه ویژگی هایی را یاد میگیرند.
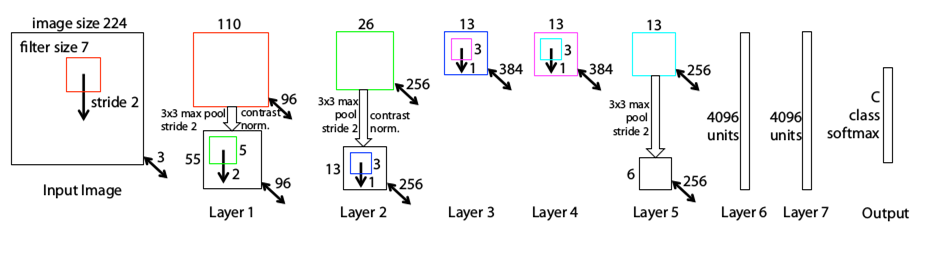
نکات اصلی:
👌مشابه معماری AlexNet ، با تغییرات جزیی کم.
👌AlexNet توسط 15 میلیون عکس آموزش داده شد ، در صورتیکه این معماری فقط توسط 1.3 میلیون عکس آموزش داده شد.
👌به جای استفاده از فیلترهایی با اندازه 11×11 در اولین لایه (استفاده شده در AlexNet) ، این معماری از فیلتر هایی با اندازه 7×7 و اندازه گام کمتر استفاده کرد . دلیل این تغییرات این است که فیلتر با اندازه کوچکتر کمک میکند که اطلاعات بیشتری از پیکسلهای اصلی تصاویر ورودی حفظ شوند.به عنوان مثال با استفاده از یک فیلتر با اندازه 11×11 اطلاعات زیادی از تصاویر مخصوصا در اولین لایه از بین میروند.
👌با رشد شبکه تعداد فیلتر ها افزایش پیدا میکنند.
👌استفاده از تابع فعال سازی ReLU ، cross-entropy برای محاسبه میزان خطا و batch stochastic gradient descent برای آموزش
👌این معماری توسط یک کارت گرافیک GTX 580 برای 12 روز آموزش داده شد.
👌یک تکنیک به نام Deconvolutional Network برای ویژوال سازی پیشنهاد شد . این تکنیک به این علت deconvnet نامیده میشود که ویژگی های استخراج شده را به پیکس های تصویر نگاشت میدهد مخالف آنچه که یک لایه کانولوشن انجام میدهد.(البته عبارت Deconvolutional یک نام بحث بر انگیز است و در واقع بایستی transposed convolution نامیده شود)
معماری VGG
Simonyanو همکارانش در رقابت ILSVRC 2014 با این دیدگاه که معماری عمیق تر باعث افزایش دقت میشود معماری VGGرا ارایه دادند که به خطای 7.3 درصدی دست یافت. این معماری 19 لایه ای از فیلتر هایی با اندازه 3×3 با گام 1 به همراه maxpooling 2×2 و گام 2 استفاده شد.
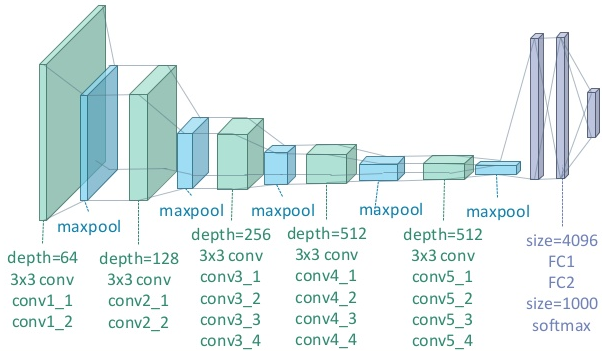
نکات اصلی:
👌استفاده از فیلترهای با اندازه 3×3 ، اما شیوه استفاده این فیلتر ها نیز نسبت به فیلتر های 11×11 AlexNet و فیلتر های 7×7 ZF netمتفاوت است.دلیل نویسنده این است که ترکیب دو لایه کانولوشن 3×3 ، همانند میدان تاثیر یک فیلتر 5×5 است . این تکنیک به نوبه خود یک فیلتر با اندازه بزرگتر را شبیه سازی میکند در حالیکه از مزایای فیلتر با سایر کوچکتر نیز بهره مند میشویم. یکی از تاثیرات این تکنیک کاهش تعداد پارامتر ها است.همچنین با استفاده از دو لایه کانولوشن میتوان از دو لایه ReLU استفاده کرد.
👌سه لایه کانولوشن پشت سر هم یک میدان تاثیر 7×7 را دارد.
👌از لایه های ReLU بعد از هر لایه کانولوشن استفاده شد و مدل توسط الگوریتم batch gradient descent آموزش داده شد.
👌نکته جالب این است که تعداد فیلتر ها یعد از هر لایه maxpool دو برابر میشود.این باعث میشود که بعد فضایی کاهش و عمق رشد کند.
👌از scale jittering به عنوان یکی از متد های افزایش مصنوعی داده ها در طول آموزش استفاده کرد.
👌این شبکه توسط چهار کارت گرافیک Nvidia Titan Black برای دو تا سه هفته آموزش داده شد.
👌این مقاله تاثیر گذارترین مقاله منتشر شده در این رقابت است و دو مفهوم اساسی سادگی و عمق را معرفی کرد.
معماری GoogLeNet
Szegedy و همکاران در سال 2014 گوگل GoogLeNet را معرفی کرد این معماری شامل 22 لایه است و به خطای 6.7 درصدی دست پیدا کرد. این معماری برای اولین بار از معماری های رایج فاصله گرفت ، معماری هایی که لایه های کانولوشن و pooling را بر روی هم به صورت یک ساختار ترتیبی سوار میکردند. نویسنده مقاله نیز تاکید میکند در این معماری توجه خاصی به حافظه مصرفی شده است. (نکته ای که اینجا وجود دارد این است که انباشتن تعداد زیاد لایه ها بر روی یکدیگر و اضافه کردن تعداد زیادی فیلتر باعث افزایش محاسبات، حافظه مصرفی و افزایش شانس بیش برارزش شدن مدل میشود)
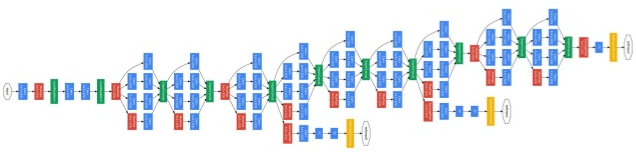
این معماری با سایر معماری های ارایه شده قبلی متفاوت است و تمامی لایه ها دیگر به صورت ترتیبی نیستند. در این معماری لایه هایی وجود دارد که به صورت موازی قرار گرفته اند هر کدام از بلاک های Inception module “برای درک این ماژول ویدیو را حتما بینید “ نام دارند. در شکل زیر یک ماژول Inception کامل نمایش داده شده است:
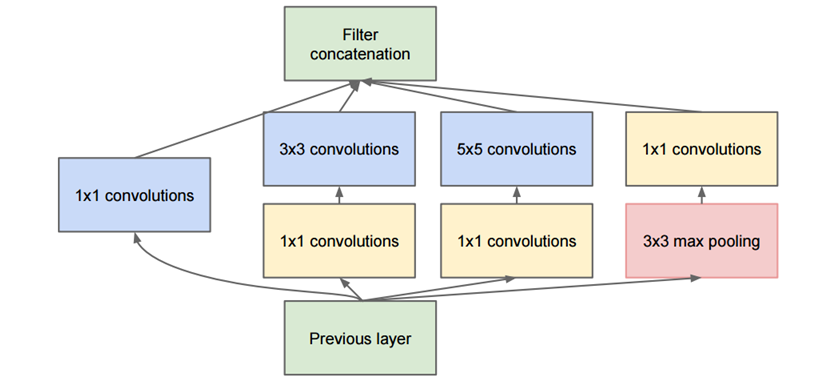
باکس سبز رنگ در قسمت پایین شکل ورودی و باکس سبز رنگ در بالای شکل خروجی مدل هست.اساسا در هر لایه کانولوشن سنتی شما مجبورید یک انتخاب بین عملیات pooling و عملیات کانولوشن (و اندازه فیلتر)داشته باشد. اما ماژول Inception این اجازه را به شما میدهد که تمامی این عملیات را به صورت موازی انجام دهید. به این دلیل این عملیات باعث افزایش بسیار زیاد تعداد زیادی خروجی ها میشوند. برای برطرف کردن این مشکل نویسندگان مقاله یک کانولوشن 1×1 قبل از لایه های 3×3 و 5×5 اضافه کردند.این کانولوشن 1 ×1باعث کاهش ابعاد میشود.برای مثال، فرض کنید ورودی ما به شکل 100 ×100×60 باشد با اعمال کردن 20 فیلتر 1×1باعث کاهش ابعاد به 100×100×20 میشود. این بدین معنی است که کانولوشن های 3 ×3 و 5 ×5 دیگر نیایستی با ورودی با حجم بالا کا کنند. در اینجا ماژولی داریم که شامل یک شبکه در لایه،یک فیلتر با اندازه کوچک،یک فیلتر با اندازه بزرگ و یک عملیات pooling است. این ایده “شبکه در شبکه” باعث استخراج اطلاعات در سطوح مختلف شود به صورتی که فیلتر 5*5 ناحیه تاثیر بزرگتری را میتواند پوشش دهد و اطلاعات مفید را استخراج کند ، شما لایه pooling را دارید کمک به کاهش اندازه فضا و کاهش بیش برارزش شدن شود. از همه مهمتر بعد از هر لایه کانولوشن تابع فعال ساز ReLU وجود دارد که غیر خطی بودن شبکه را افزایش میدهد.اساسا شبکه قادر به انجام عملیات متفاوت خواهد بود.
نکات اصلی :
👌از 9 ماژول Inception استفاده کرد که در مجموع دارای بیش 100 لایه بود
👌بیشترین تعداد پارامتر ها در هر معماری در لایه های تماما متصل قرار میگیرند.این معماری به جای استفاده از لایه های تماما متصل از یک average pool استفاده کرد. این متد باعث کاهش تعداد پارامترها به صورت چمشگیر شد.
👌نسبت به معماری Alexnet تعداد پارامتر ها 12 درصد کاهش یافت
👌این معماری بر روی تعدادی کارت گرافیک برای یک هفته آموزش داده شد.
معماری ResNet
در سال 2015 تعدادی از محققین مایکروسافت معماری ResNet را ارایه دادند که خطا را به 3.6 درصد کاهش داد. این معماری از 152 لایه تشکیل شده است که یک رکورد در هر سه بخش تشخیص اشیاء،کلاسه بندی و localization با استفاده از یک مدل به جا گذاشت. این مدل در حقیقت قدرت انسان در تشخیص اشیاء را جا گذاشت و با دقت به مراتب بالاتر از انسانها اشیاء را تشخیص داد.
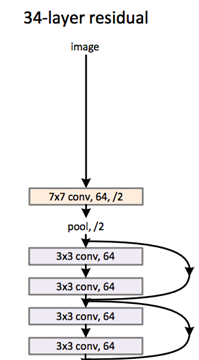
ایده اصلی یک بلاک residual این است که ودودی نوسط یک لایه کانولوشن ، لایه ReLU و یک لایه کانولوشن پردازش میشود ، نتیجه این تبدیلات یک تابع F(x) تولید میکند . نتیجه این تابع با ورودی لایه قبل جمع میشود . نویسنده مقاله اعتقاد دارد بهینه سازی بلاک residual نسبت به از معماری های قبلی ساده تر است
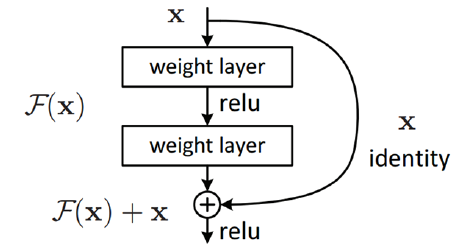
دلیل دیگر برای اینکه چرا این معماری نسبت به معماری های قبل تاثیرگذارتر است این است که در طول اجرای الگوریتم پیش خورد به علت وجود عملیات جمع گرادیان میتواند براحتی در طول گراف حرکت کند
نکات اصلی:
👌عمق زیاد.
👌152 لایه
👌بعد از دو لایه اول فضای ورودی فشرده میشود (از ودودی با اندازه 224 ×224 به 56 ×56
👌نویسنده مقاله اعتقاد دارد در سایر معماری ها با اضافه کردن لایه باعث بالارفتن زمان آموزش و خطای آزمایش میشود.
👌نویسندگان مقاله شبکه ای با 1202 لایه را طراحی کردند اما دقت آزمایش کاهش یافت (احتمالا به خاطر بیش بر ارزش شدن)
👌این مدل توسط 8 کارت گرافیک برای دو تا سه هفته آموزش داده شد.
این معماری بهترین معماری شبکه عصبی کانولوشن موجود است.