بررسی مقاله CAN-Creative Adversarial Networks
مقاله ای که امروز بررسی خواهیم کرد Creative Adversarial Network است ، مقاله ای که شش روز پیش (21 ژوئن) منتشر شد.
اخیرا GANS در ایجاد محتوای جذاب بسیار موفق بوده اند شبکه هایی که در گام اول کمی انتزاعی و از نظر پیاده سازی مشکل به نظر میرسند.قبل از وارد شدن به مفاهیم ریاضی و جزییات شنیدن خلاصه ای گفتگوی Goodfellow با The AI podcast خالی از لطف نیست ! پیشنهاد میکنم این پادکست را دنبال کنید، برنامه ای که هر هفته گفتگویی کوتاه با یکی از دانشمندان علوم داده انجام میدهد و جدید ترین تحولات مورد بررسی قرار میگیرند.این پادکست از طریق iTunes و Soundcloud قابل استریم است.
این گفتگو با یه شوخی شروع میشه، فردی به یک بار میرود و شروع به بحث و گفتگو با دوستانش میکند، در نهایت این گفتگو به ایده انقلابی با نام GAN ختم میشود، ایده ای که یان لیکون از اون به عنوان جالب ترین ایده ۲۰ سال اخیر نام میبرد.
در این قسمت Goodfellow در مورد یکی از مشکلات و موانع اصلی یادگیری عمیق صحبت میکنه که نیاز آن به حجم زیادی داده ها برچسب دار برای آموزش است که نیاز به ساعت ها کار توسط انسان است به عنوان مثال :Amazon Mechanical Turk
اگه شما یک شبکه عصبی را انتخاب کنید و به اون آموزش دهید که بتواند حروفی که در یک تصویر هست را بخواند ، این شبکه میتواند این کار را با دقت انسان انجام بدهد اما فرآیند یادگیری آن به هیچ وجه نزدیک به فرآیندی که انسانها برای یادگیری انجام میدهند نیست !
GANS
این اجازه را به شبکه های عصبی عمیق میدهد که یادگیری دادها با نرخ سریعترو با دخالت کمتر انسانها انجام شود. عبارت “adversarial” به این علت بکار برده میشود که دو شبکه در مقابل یک دیگر کار میکنند . شبکه generator مسئولیت ایجاد عکس را بر عهده دارد در حالی که شبکه discriminator مسئولیت اعتبار سنجی عکس را بر عهده دارد . ( در واقع یه منتقد هنر !) شبکه discriminator به عکس نگاه میکند و به ما میگوید که این عکس واقعی یا جعلی هست کار دیگه ای که این شبکه انجام میدهد به شبکه generator میگه که چه کاری را باید انجام دهد تا عکس ایجاد شده توسط این شبکه واقعی تر به نظر برسد .این خلاصه ای از گفتگوی با این محقق بود . Goodfellow همچنین در مورد استفاده از GANs در امنیت سایبر ی صحبت میکند و اینکه چطور میتوانیم از GANs در این زمینه نیز استفاده کرد . گفتگوی اصلی ۲۳ دقیقه است که از طریق این لینک قابل استریم هست.
خلاصه GAN از دیدگاه ریاضی !
GAN شامل دو شبکه عصبی به نام های Generator و Discriminator است . همانطور که از نام آنها پیداست شبکه Generator مسئول ایجاد داده معتبر از ورودی است، ورودی که میتواند نویز یا داده دیگر باشد.شبکه discriminator مسئول تجزیه و تحلیل داده ها است و مشخص میکند که داده های تولید شده واقعی یا جعلی هستند.
نکته مهم
به این نکته توجه کنید چون ایده مقاله جدید که در ادامه بحث خواهد شد در دل این نکته نهفته شده است ! منظور از واقعی بودن این است که شبکه discriminator بررسی میکند که داده مربوط به داده های دیتابیس است و منظور از جعلی بودن داده هایی است که توسط generator به این شبکه وارد میشوند.
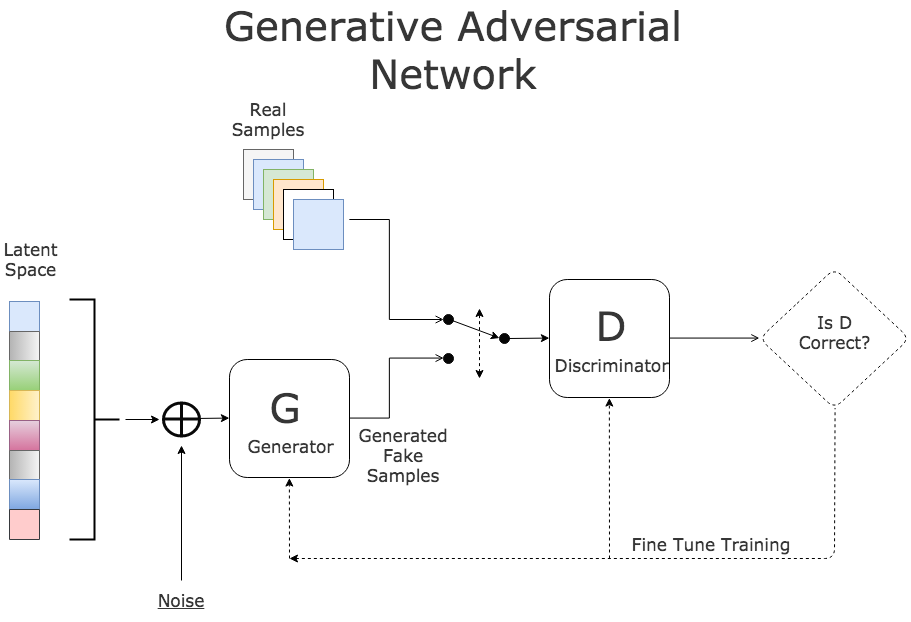
این شبکه در واقع چیزی شبیه بازی minimax است که دو شبکه Generator و Discriminator شرکت کننده گان اصلی آن هستند (مینیماکس یک قانون تصمیم گیری است که در نظریهٔ بازیها و آمار برای مینیمم کردن احتمال شکست و ضرر در بدترین حالت که بیشترین احتمال ضرر را دارد از آن استفاده میشود) که در معادله زیر خلاصه میشود(😱):
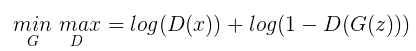
بگذارید این معادله رو باز کنیم و به صورت گام به گام هر جزء را مورد بررسی قرار دهیم . برای شروع به معادله زیر توجه کنید :
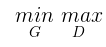
معدله بالا همان معادله minimax است! حروف G و D به صورت متناظر به Generator و Discriminator اشاره دارند. کار Generator این است که مقدار معادله را کمینه کند، در حالی که کار Discriminator پیشینه کردن مقدار معادله است. این دو شبکه به صورت پایان ناپذیر با یک دیگر رقابت می کنند تا زمانی که ما به نتیجه مطلوب برسیم و آنها را متوقف کنیم.
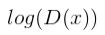
خروجی Discriminator زمانی توسط این شبکه به صورت واقعی بر چسب میخورند که ورودی ما (x) از داده های واقعی دیتا بیس باشد.
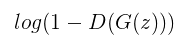
تابع بالا محاسبه میکند چگونه شبکه discriminator بر روی ورودی که از سمت generator به آن داده میشود عمل کرده است. D(G(z)) یه داده ای اشاره دارد که discriminator فکر میکند آنها واقعی هستند. 1- D(G(z)) به داد ای اشاره دارد که discriminator فکر میکند واقعی نیستند. G(z) به داده ای که توسط generator ایجاد شده اشاره دارد.
اگه تمام این اجزاء را در کنار هم قرار دهیم متوجه میشیم که وظیفه Discriminator این است که مقدار معادله زیر را تا جایی که امکان پذیر هست افزایش دهد :
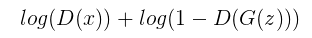
در حالی که وظیفه Generator این است که مقدار معادله بالا را تا جایی که ممکن است مینیمم کند با ماکسیمم کردن مقدار :
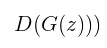
در صورتی که علاقه مند هستید جزییات تکمیلی در مورد این شبکه ها را مطالعه کنید،من خوندن صفحه ویکی دانشگاه بریتیش کلمبیا را پیشنهاد میکنم . در حین فرآیند شبکه Generator سعی میکند که پارامتر های خودش را اصلاح کند و نتایجی خودش را اینقدر دقیق کند که شبکه Discriminator آن داده را به عنوان یک داده واقعی تشخیص دهد، در حالی که شبکه Discriminator پارامتر های خودش را اصلاح میکند تا تفاوت بین داده واقعی و داده ای توسط Generator تولید شده است را بیان کند. ساده است، اینطور نیست؟ 😋
به عبارتی هدف generator این است که Discriminator را فریب دهد که داده ای که توسط این شبکه تولید شده است داده واقعی است و این کار با نزدیک کردن خروجی خودش به داده واقعی انجام میدهد. در واقع میشه گفت شبکه اول یک جاعل حرفه ای 😈 و شبکه دوم یک کارگاه 👮 است.
مسئله هنگامی بوجود می آید که شما میخواهید شبکه شما خلاق باشد! با این شیوه نه تنها شبکه generator خلق آثار جدید را یاد نمیگیرد بلکه تمام تلاش خودش را به کار میگیرد که خروجی خودش را شبیه داده واقعی کند!
راه حل Creative Adversarial Networks
نویسندگان این مقاله یک مدل اصلاح شده از GAN را برای خلق آثار خلاقانه پیشنهاد میدهند. نویسندگاه مقاله یک سیگنال اضافه را به generator ارسال میکنند که این امر جلوی کپی برداری داده های واقعی توسط generator را میگیرد. این کار فقط توسط اصلاح کردن تابع هزینه مقاله GAN انجام میشود!
قبل از توضیح معادله اصلاح شده بگذارید به صورت ساده یک نگاه به اتفاقاتی که در CAN می افتد داشته باشیم. در مقاله اصلی GAN شبکه generator وزن های خودش را با توجه به خروجی شبکه discriminator که آیا توانسته این شبکه را فریب دهد یا نه ،بروز رسانی میکند.مقاله CAN این بخش را به دو صورت گسترش میدهد:
👌شبکه discriminator نه تنها تفاوت داده واقعی و جعلی را بیان میکند بلکه اثری که توسط شبکه generator تولید شده است را با توجه به دوره تاریخی آن اثر کلاسه بندی میکند.
👌 شبکه generator اطلاعات اضافی که مربوط به دوره تاریخی اثر را از discriminator دریافت میکند، و از آن مقیاس به همراه داده ورودی واقعی/جعلی discriminator استفاده میکند.
من اطلاعات زیادی در مورد فلسفه ندارم و خودم را یک armchair philosopher میدونم، سعی میکنم در توضیح پاراگراف زیر دست به عصا حرکت کنم !
متدی که توسط این محققین ارایه شد در واقع از تئوری دنیل برلین فلسفه دان و روانشناس کانادایی-انگلیسی الهام گرفته شده است. به طور خلاصه این فلسفه دان در مورد مفهوم برانگیختگی و تاثیر آن در مطالعه زیباشناسی صحبت میکند.سطوح بر انگیختگی نشان میدهد که انسان چقدر هوشیار و هیجان زده است. انسان سطوح برانگیختگی متفاوتی دارد، هنگامی که او خواب است این سطح در پایین ترین مقدار آن قرار دارد و هنگامی که خشمگین است این سطح به بالاترین حد خود میرسد. هنر موفق، هنری است که مکالمهای دوجانبه با ذهن به وجود آورد، چالشهای ذهنی به وجود آورد و بازتابهایی ایجاد کند. این رابطه معمولاً از تجزیه و تحلیل ناکامل نیروهای مؤثر، حاصل میشود. ترکیبی که کاملاً هماهنگ و وحدت یافته باشد، ترکیبی خسته کننده خواهد بود. هنرمند موفق کسی است که احساس نظم و وابستگی را القا کند و در همان حال چیزهای غیرمنتظره را در اثر خود وارد سازد.😯
برلین تاکید داشت که مهمترین خصوصیات افزایش انگیزه برای زیباشناسی تازگی،شگفتی،پیچیدگی، ابهام و گیجی هستند.در این مقاله نویسندگان تلاش میکنند که خروجی که تولید میشود شامل یک درجه از ابهام داشته باشد و از سبک معمولی فاصله گیرد به عبارتی عامل سعی میکند فضای خلاقیت را با انحراف از قوانین وضع شده رایج جستجو کنید.
هدف از این کار چیست؟
اگر بخاطر بیاورید مشکل اصلی GAN این بود که نمیتوانست آثار جدید را بررسی کند. تابع هدف این است که داده ای که تولید شده است شبیه داده موجود در دیتا بیس باشد.
با داشتن یک مقیاس جدید که داده ها را بر حسب دوره زمانی کلاسه بندی میکند، شبکه generator اکنون یک بازخورد نیز دریافت میکند که داده ایجاد شده تا چه میزان شبیه برخی از آثار ادوار تاریخی مورد نظر است.
اکنون شبکه generator نه تنها بایستی تلاش کند که داده خودش را به داده موجود در دیتابیس شبیه کند،بلکه باید مطمئن شود که داده ایجاد شده خیلی شبیه به یه دسته خاص نیست. این امر شبکه را از ایجاد کردن آثاری که مشخصات خیلی خاص دارند باز میدارد.
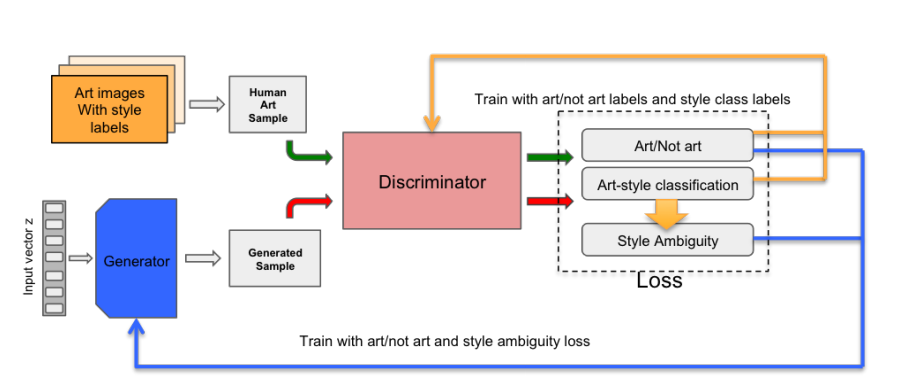
اکنون یک نگاه به تابع هزینه بیندازیم: 🙀
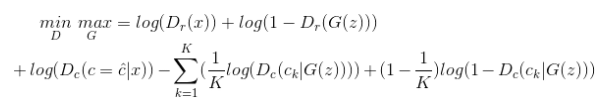
خط اول همان معادله GAN است که قبلا شرح داده شد.و اما بخش دوم معادله! توجه کنید که زیر نویس C همان خروجی کلاسه بندی شبکه discriminator است و r خروجی واقعی یا جعلی بودن discriminator است. خط دوم معادله در واقع بخشی است که خلافیت شبکه در آن نهفته شده است . بگذارید آن را به دوبخش تقسیم کنیم:
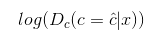
این بخش Discriminator است که کلاس عکس ورودی را به درستی پیش بینی میکند. Discriminator تلاش میکند که این مقدار را ماکسیمم کند. ما انتظار داریم که discriminator عکس ورودی را به صورت صحیح کلاسه بندی کند.
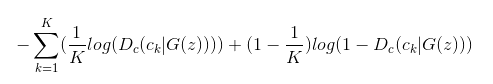
این بخش قسمت از معادلی مشکل به نظر میرسد، اما در حقیقت یک قسمت فقط یک multi lable cross entropy loss هست که حرف K به تعداد کلاس ها اشاره دارد.در این لینکتوابع هزینه با جزییات کامل شرح داده شده است. generator تلاش میکند که مقدار این عبارت را مینیمم کند.
این شبکه توسط آثاری که به صورت عمومی در WikiArt وجود دارند آموزش داده شد. در این سایت 81449 اثر از 1119 هنرمند از قرن 15 تا بیستم وجود دارد.در شکل زیر نمونه ای از خروجی های ایجاد شده توسط CAN نمایش داده شده است.

در پایان از دوست خوبم Harshvardhan Gupta به خاطر منابع که در اختیار من گذاشت و توضیحاتشون تشکر میکنم.