معماری MobileNets و Xception -بخش اول-
- MobileNet
- Xception
- کانولوشن
- گوگل
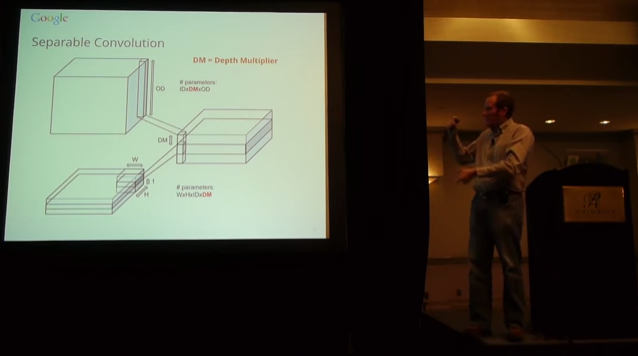
مقاله ای که اخیرا توسط گوگل منتشر شد یک معماری جدید است به نام MobileNets که برای سیستم هایی تعبیه شده مثل موبایل بهینه سازی شده است. در هسته اصلی این معماری از کانولوشن بر حسب کانال تفکیک پذیر (depthwise separable convolution) برای ساخت یک شبکه عصبی سبک استفاده شده است .
من همیشه به شبکه های عصبی کانولوشنال سبک (lightweight) علاقه مند بودم، چند روز پیش تصمیم گرفتم که مقاله MobileNets را مطالعه کنم اما در میانه راه مجبور شدم مقاله Xception ، که توسط François Chollet (نویسنده کتابخانه متن باز شبکه عصبی کراس و موسس Wysp که یک پلتفرم برای هنرمندان است) منتشر شده است، را بخوانم . این پست در واقع جمع بندی این دو مقاله است.
با شکل گیری شاخه یادگیری عمیق اصطلاحات زیادی به وجود آمد که معادل فارسی برای آنها وجود ندارند (یا من از آنها بی اطلاع هستم 😟 ). در این پست سعی کردم برای هر کدام از این عبارات معادل فارسی که توصیف کننده آن کلمه هست استفاده کنم ، در صورتی که معال بهتری برای آنها در ذهن دارید یا قبلا وجود داشته است لطفا به من اطلاع دهید تا اصلاح کنم. 👌🏻
در هر دوی این مقاله برای کاهش تعداد پارامتر های شبکه کانولوشنال از دو عملیات کانولوشن به نام های کانولوشن نقطه ای(pointwise) و کانولوشن بر حسب کانال(depthwise) استفاده میشود که در حین کاهش قابل توجه پارامتر ها،دقت نیز در حد مطلوب باقی میماند. به عبارتی بده و بستان بین دقت و پارامتر ها بهبود پیدا میکند!
ساخت یک شبکه سبک (یک شبکه با تعداد پارامتر کمتر) برای تلفن های همراه، دستگاه هایی که قدرت محاسباتی آنها محدود است یک زمینه باز در مبحث یادگیری عمیق است. با کاهش تعداد پارامتر ها این امکان نیز وجود دارد که شبکه ای عمیق تر ایجاد کنیم در نتیجه دقت نیز میتواند افزایش پیدا کند .
متد های زیادی برای ایجاد این چنین شبکه هایی وجود دارند، اما میتوان آنها را به دو بخش عمده تقسیم کرد:
1- کاهش تعداد پارامتر ها با ابداع ساختار جدید لایه کانولوشن به عنوان مثال متد هایی که در مقاله های GoogLeNet،ResNet، SqueezeNet،MobileNets ،Xception وShuffleNetمعرفی شدند.
2- فشرده سازی پارامتر ها به عنوان مثال میتوان به مقاله های مثل BinaryConnect،Binarized Neural Networks،EIE،Deep Compression و Compressing Deep Convolutional Networks using Vector Quantization اشاره کرد.
در واقع مقالات زیادی در چند سال اخیر در این زمینه منتشر شده است که تعدادی از آنها را به عنوان مرجع در بالا آوردم.
هنگامی که مقاله GoogLeNet در سال 2014 منتشر شد شامل ماژول هایی Inception مثل شکل زیر بود:
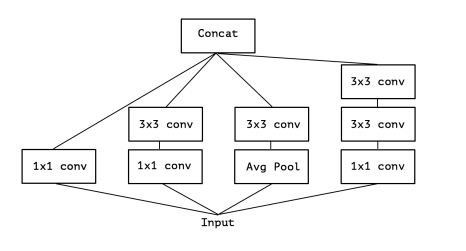
ایده اصلی پشت این ماژول این است که ابتدا توسط یک کانولوشن با اندازه فیلتر 1x1 همبستگی میان کانالی(cross-channel)و سپس همبستگی مکانی(spatial correlations) توسط یک کانولوشن یا اندازه فیلتر 3x3 محاسبه میشود. این دو عملیات جدا از یکدیگر انجام میشوند ، استفاده از کانولوشن با اندازه فیلتر 1x1به این دلیل است که این فیلتر یک پیکسل و تمامی کانال های آن (به عنوان مثال در یک عکس رنگی کانال ها R و G و B هستند) را به یک پیکسل خروجی نگاشت میدهد. از این عملیات عمدتا برای کاهش تعداد ابعاد فیلتر(عمق) استفاده استفاده میشود .
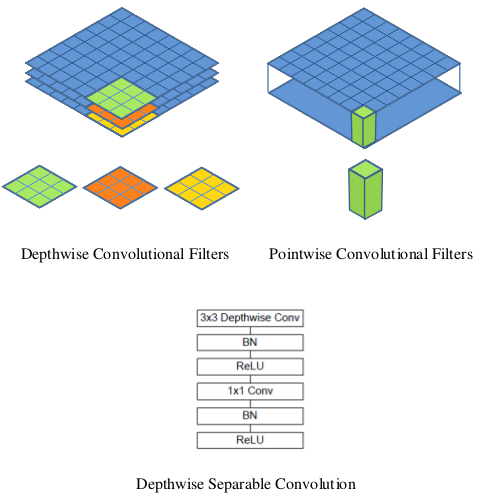
کانولوشن بر حسب کانال (Depthwise) و نقطه ای(pointwise)
برای درک شایستگی و ارزشمند بودن کانولوشن بر حسب کانال و نقطه ای ابتدا نیاز است که پیچیدگی محاسباتی لایه کانولوشن و تعداد پارامتر ها را بررسی کرد.نماد هایی که در ادامه استفاده خواهد شد متفاوت از متن خود مقالات است!
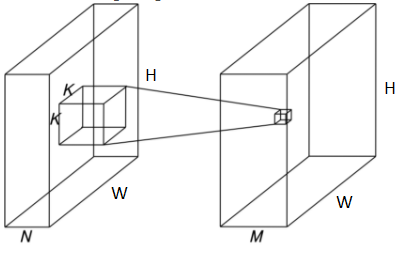
برای درک بهتر این عملیات مثال زیر را در نظر بگیرید :در یک لایه کانولوشن، فرض کنید مقادیر زیر را دارید:
اندازه نقشه ویژگی ورودی:W x H
تعداد کانال های ورودی : N
اندازه فیلتر:K xK
تعداد کانال های خروجی: M(تعداد فیلتر ها)
با توجه به موارد ذکر شده در مثال بالا، پیچیدگی محاسباتی یک لایه کانولوشن معمولی
WxHxNxK^2xM خواهد بود. به عبارتی هزینه عملیات کانولوشن برای هر مکان در نقشه ویژگی ورودی K^2xN،اعمال کردن این عملیات به نقشه ویژگی ورودی با WxH مکان باعث ایجاد یک نقشه ویژگی از یک کانال میشود از طرفی خروجی ما دارای M کانال است .
تعداد پارامتر ها: M نوع کانولوشن با تعداد پارامتر K^2xN وجود دارد که نتیجه آن K^2xNxM خواهد شد.
کانولوشن نقطه ای در واقع همان کانولوشن 1x1است که اولین بار در GoogLeNet استفاده شد. نکته این عملیات در مسیر عمق کانال ورودی انجام میشود . از این عملیات برای کاهش ابعاد نقشه ویژگی استفاده میشود. از آنجایی که کانولوشن نقطه ای در واقع مشابه یک کانولوشن معمولی با اندازه فیلتر K=1 است پیچیدگی محاسبات WxHxNxM و تعداد پارامتر ها NxM خواهد بود.
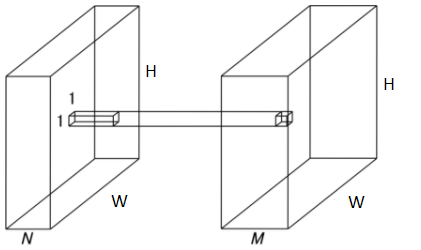
کانولوشن بر حسب کانال عملیات را در مسیر ابعاد نقشه ویژگی برای هر کدام کانال به صورت مجزا انجام میدهد.پیچیدگی محاسباتی WxHxNxK^2 و تعداد پارامتر ها K^2xN خواهد بود.
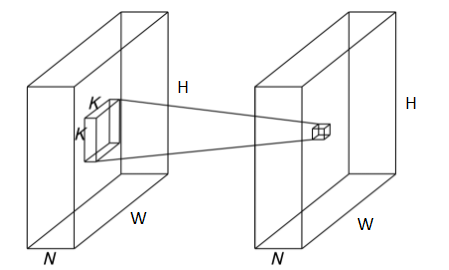
با ترکیب دو عملیات ذکر شده در بالا میتوان عملیات کانولوشن در یک لایه را با تعداد پارامتر و هزینه محاسباتی به مراتب کمتری انجام داد.با توجه به توضحات ذکر شده پیچیدگی محاسباتی از WxHxNxK^2xM به WxHxNxM+WxHxNxK^2 کاهش پیدا میکند. فرض کنید یک عکس 48 در 48 پیکسل با سه کانال RGB و 64 فیلتر 3x3 داریم پیچیدگی محاسباتی یک کانولوشن معمولی 3,981,312 و پیچیدگی محاسباتی با روش جدید 504,576 خواهد بود این یعنی نزدیک به 8 برابر کمتر!
دو مقاله Xception و MobileNets از این عملیات به جای کانولوشن معمولی استفاده میکنند.بیایید نگاهی به این دو معماری بیندازیم.
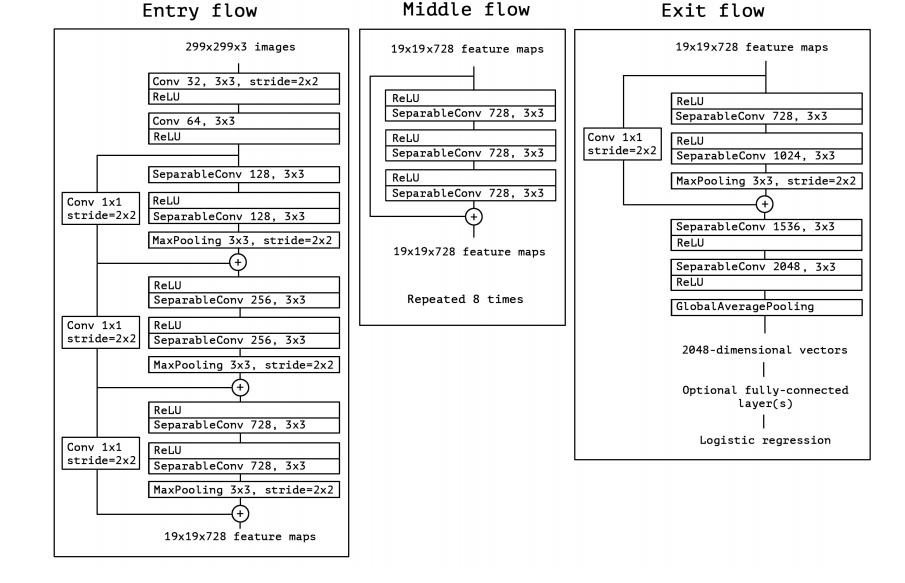
معماری Xception
معماری MobileNet
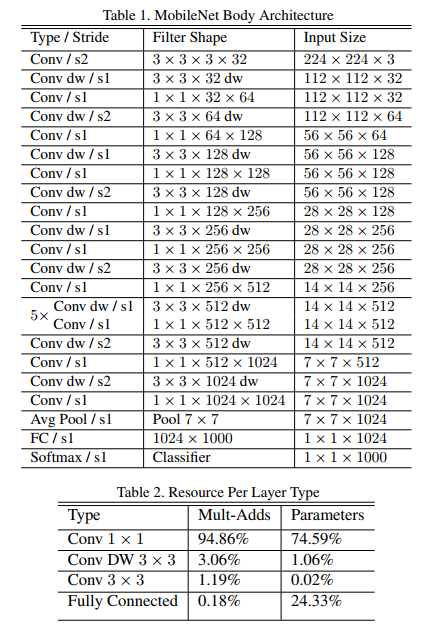
در دو شکل بالا این دو معماری نمایش داده شده اند . در شکل اول که مربوط به معماری Xception است دیتا از سه قسمت عبور میکنند ، که بخش میانی 8 بار تکرار شده است . بعد از هر لایه depthwise یک لایه pointwise و batch normalization قرار گرفته است که در شکل نمایش داده نشده است.مقایسه این دو مدل در نگاه اول غیر ممکن به نظر میرسد به همین علت ما آنها را بر اساس بلاک مقایسه میکنیم .
ماژل MobileNets :از قسمت های ذیر تشکیل شده است :
depthwise->batch normalization->ReLU->pointwise->batch normalization->ReLU
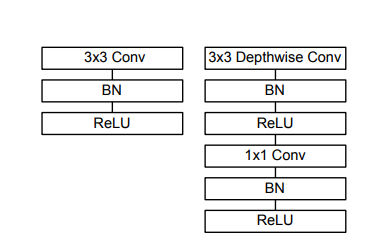
ماژول Xception از قسمت های ذیل تشکیل شده است:
ReLU->depthwise->pointwise->batch normalization->ReLU->depthwise->pointwise->batch normalization->ReLU->depthwise->pointwise->batch normalization+identity mapping
اما تفاوت عمده:
ماژول Xception دارای مفهمومی بنام skip connection است که اولین بار در معماری ResNet معرفی شد.
در ماژول Xception هیچ تابع فعال ساز بین کانولوشن depthwise و pointwise وجود ندارد.
کد مقاله MobileNet در این لینک قرار گرفته است، همچنین در تنسورفلو برای استفاده از عملیات کانولوشن پیشنهادی میتوانید از تابع separable_conv2dاستفاده کنیدکه ابتدا عملیات کانولوشن بر حسب کانال به صورت جداگانه بر روی هر کانال ورودی و سپس عملیات کانولوشن نقطه ای را بر روی انجام میدهد:
tf.nn.separable_conv2d(input, depthwise_filter, pointwise_filter, strides, padding, rate=None, name=None)
در پایان نکات جالبی است که در مقاله قید نشده است را برایتان بازگو میکنم :
این متد اولین بار توسط دکتر Laurent Sifre در سال 2013 پیشنهاد داده شد و در معماری الکس نت اعمال شد اما در این مقاله چیزی در این باره قید نشده است! به عنوان مرجع فصل ششم،بخش دوم پایان نامه دکترا ایشان را مطالعه کنید. این متد همچنین در کنفرانس ICLR 2014 توسط Vincent Vanhoucke شرح داده شد . برای جزییات بیشتر دقیقه 20 این ویدیو را ببینید