معماری MobileNets و Xception -بخش دوم-
- MobileNet
- Xception
- کانولوشن
- گوگل
در پست قبلی دو عملیات کانولوشن به نام های کانولوشن نقطه ای(pointwise) و کانولوشن بر حسب کانال(depthwise) را بررسی کردیم و نشان دادیم که با جدا کردن کانولوشن در دو جهت مکانی و کانال تعداد پارامتر ها و هزینه محاسبات کاهش پیدا میکند.
یک کانولوشن با اندازه 5 ×5 نسبت به یک کانولوشن 3×3 پرهزینه تر است. جایگزین کردن کانولوشن 5×5 با دو لایه کانولوشن 3×3 و استفاده از تابع فعال ساز در میان آنها میدان تاثیر مشابهی دارد اما از هزینه محاسباتی به مراتب کمتری برخوردار است. به همین ترتیب سه لایه متوالی کانولوشن 3×3 ناحیه تاثیر مشابه یک لایه کانولوشن 7×7 دارند.
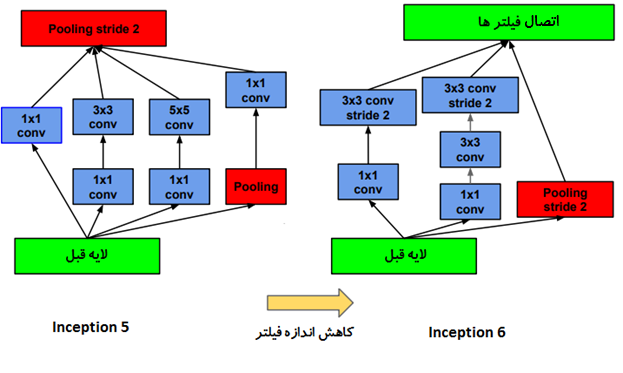
نکات اصلی:
👈ناحیه تاثیر مشابه
👈داشتن شبکه عمیق تر و استفاده از ReLU در هر دو لایه
👈 28 درصد ارزانتر به خاطر اشتراک ویژگی ها
👈هزینه محاسبات را میتوان با افزایش تعداد فیلتر ها کاهش داد
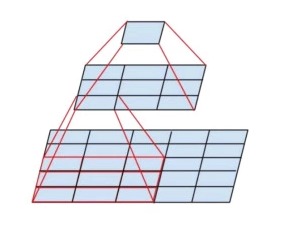
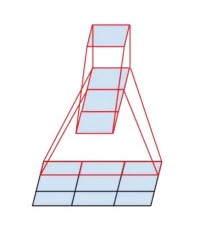
نتایج بدست آمده نشان میدهد که عملیات کانولوشن با فیلتر بزرگتر از 3 × 3 شاید بطور کلی سودمند نباشند و میتوانند با یک رشته از لایه های 3 × 3 کانولوشن جایگزین شوند.یک سوال بوجود میاید،با توجه به موارد ذکر شده در بالا آیا میتوان از کانولوشن هایی با اندازه کوچکتر مثلا 2×2 استفاده کرد؟🤔
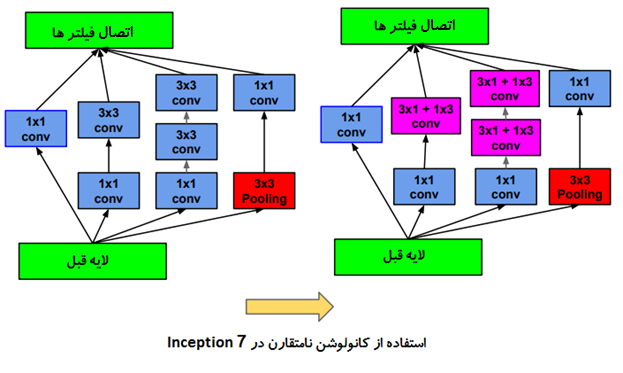
به عنوان یک رویکرد مشابه، Christian Szegedy و همکارانش در مقاله ای با عنوان بازنگری معماری Inception برای بینایی ماشین نشان دادند که با جدا سازی عملیات کانولوشن به کانولوشن طولی و عرضی ، تعداد پارامتر ها کاهش می یابد در حالی که ناحیه تاثیر ثابت باقی میماند.این عملیات به عملیات کانولوشن نا متقارن(asymmetric convolution) معروف است. به عنوان مثال استفاده از یک کانولوشن 3 × 1 و به دنبال آن یک کانولوشن 1 × 3 مشابه لغزاندن دو لایه کانولوشن با ناحیه تاثیر 3×3 است ، اما این عملیات 33 درصد ارزان تر است!
نکات اصلی:
👈استفاده از دو کانولوشن نامتقارن ناحیه تاثیر مشابهی دارند
👈داشتن شبکه عمیق تر و استفاده از ReLU در هر دو لایه
👈 33 درصد ارزانتر به خاطر اشتراک ویژگی ها
👈هزینه محاسبات را میتوان با افزایش تعداد فیلتر ها کاهش داد
به این ترتیب میتوان از دو کانولوشن 1×7 و 7×1 به جای کانولوشن 7×7 استفاده کرد.
مقایسه متد های پیشنهاد شده در عمل
به عنوان یک تحقیق،بیاییم متد های ارایه شده در چند مقاله ای که با هم مرور کردیم را در عمل پیاده سازی کنیم . بدین منظور در ادامه ما یک شبکه عصبی کانولوشنال با 16 لایه ایجاد میکنیم . ورودی ما عکس هایی (داده های تصادفی) با اندازه 32 در 32 هستند در این پروژه هدف ما کلاسه بندی داده ها نیست ما فقط میخواییم سرعت هر کدام از این متد ها را با یکدیگر مقایسه کنیم . هیچ لایه فعال ساز و batch normalization وجود ندارد ، از طرفی چون هیچ عملیات یادگیری انجام نمیشود نرخ یادگیری به صورت پیش فرض قرار داده میشود.این عملیات را برای صد بار با اندازه batch 32 تکرار میکنیم و تعداد کانال های ما از 8 به 64 تغییر میکنند. ابتدا عملیات را بر روی CPU و سپس GPU انجام میدهیم. برای پیاده سازی از فریم ورک TensorFlow/Keras و سیستمی با کانفیگ زیر برای آموزش مدل استفاده میکنیم:
Core i7:CPU
GeForce GTX 1080:GPU
متد های که مقایسه خواهیم کرد به شرح ذیل هستند:
👈 conv3x3 کانولوشن معمولی: 3 × 3
👈 conv1x3, conv3x1:کانولوشن 3 × 3 که به دوشکل افقی و عمودی اعمال میگردد
👈 conv3x3sepکانولوشن برحسب عمق: 3 × 3
👈 conv1x1:کانولوشن 1×1(کانولوشن نقطه ای)
👈 conv5x5:کانولوشن 5 ×5
نتایج نهایی: در جدول زیر زمان محاسبه شده به ثانیه نمایش داده شده است.
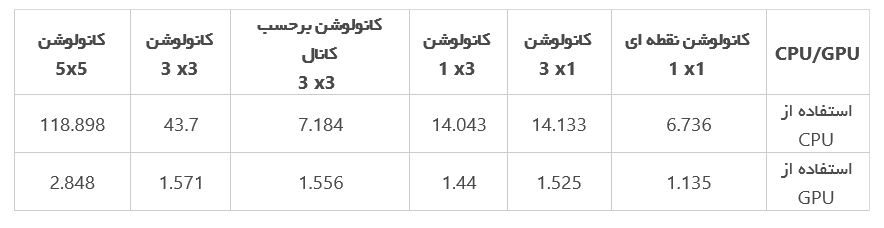
Cpu
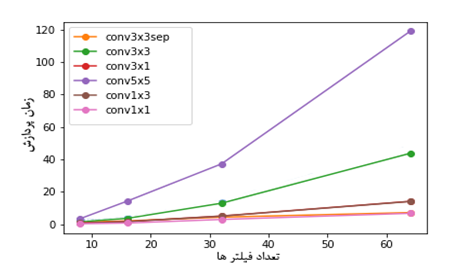
همانطور که در شکل بالا نمایش و همانگونه که در تئوری ذکر شده بود با کاهش اندازه فیلتر،سرعت پردازش بر بق آن بالا میرود. با توجه به شکل جایگزین کردن کانولوشن 5 × 5 با دو کانولوشن 3 × 3 باعث بالا رفتن سرعت پردازش میشود یا جایگزین کردن کانولوشن 3 × 3 با دو کانولوشن 3 × 1 و 1 × 3 نیز تاثیر مشابهی دارد.
Gpu
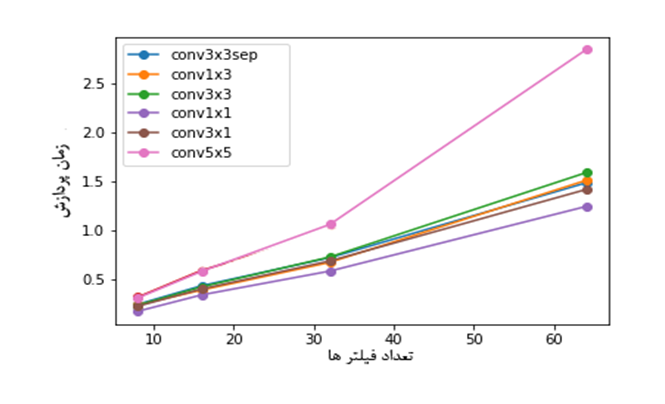
همانگونه که در شکل بالا نمایش داده شده است جایگزین کردن کانولوشن 5 × 5 با دو کانولوشن 3 × 3 ایده جالبی به نظر نمیرسد،هر چند مدل ما در مقابل سایر مدل های عمیق بیشتر شبیه یک TOY MODEL هست .چیزی که نتایج به ما نشان میدهد،استفاده از متد های ارایه شده برای دستگاهایی که بر طبق پردازنده کار میکنند جایی که سرعت بالا مد نظر است تاثیر قابل توجهی دارند.
کد
%matplotlib inline
from keras.models import Sequential
from keras.layers.convolutional import Conv2D
import numpy as np
import time
import matplotlib.pyplot as plt
from depthwise_conv2d import DepthwiseConv2D
import tensorflow as tf
def get_conv(filter_num, param):
return param["conv"](filter_num, param["kernel_size"], padding='same', use_bias=False)
image_size = 32
batch_num = 32
layer_num = 16
filter_nums = [8, 16, 32, 64]
device_mode = "/gpu:0"
# device_mode = "/cpu:0"
params = {
"conv5x5": {"kernel_size": (5, 5), "conv": Conv2D},
"conv3x3": {"kernel_size": (3, 3), "conv": Conv2D},
"conv3x3sep": {"kernel_size": (3, 3), "conv": DepthwiseConv2D},
"conv1x1": {"kernel_size": (1, 1), "conv": Conv2D},
"conv1x3": {"kernel_size": (1, 3), "conv": Conv2D},
"conv3x1": {"kernel_size": (3, 1), "conv": Conv2D}
}
results = {}
for name, param in params.items():
timings = []
for filter_num in filter_nums:
with tf.device(device_mode):
layers = [get_conv(filter_num, param) for _ in range(layer_num)]
input_shape = (image_size, image_size, filter_num)
model = Sequential()
model.add(param["conv"](filter_num, param["kernel_size"], padding='same',
input_shape=input_shape, use_bias=False))
for _ in range(layer_num - 1):
model.add(get_conv(filter_num, param))
input = np.random.randn(batch_num, image_size, image_size, filter_num)
out = model.predict(input, batch_size=batch_num)
start = time.time()
for i in range(100):
out = model.predict(input, batch_size=batch_num)
elapsed_time = time.time() - start
timings.append(elapsed_time)
results[name] = timings
for name in params.keys():
plt.plot(filter_nums, results[name], label=name, marker="o")
plt.xlabel("تعداد فیلترها")
plt.ylabel("زمان پردازش")
plt.legend()
#All credit goes to Yusuke Uchida ♥️♥️♥️