سال 2016 در یک نگاه- شبکه های عصبی عمیق با عمق تصادفی-بخش اول
- ResNet
- Microsoft
- کانولوشن
کامل کردن این پست زمان زیادی برد و علتش این بود مجبور شدم مقاله هایی که در سال 2016 به فهرست مقاله های محبوب خودم در Mendeley اضافه کرده بودم را مجددا مرور کنم و خلاصه ای از آنها را برایتان بنویسم.
متاسفانه زمان کافی برای شرح جزییات نداشتم اما سعی کردم کلیات به همراه ویژگی های بازر آنها افزوده شوند. تعداد مقاله ها زیاد است(بیش از 100) اما سعی میکنم کمتر از 20 مقاله ای که به نظر خودم در فهرست بهترین مقاله های سال گذشته قرار گرفته اند را در ادامه بررسی کنیم . برای اینکه مطالب این پست بیش از حد زیاد نشود ، مطالب را به تدریج در چند پست ارسال خواهم کرد.
مقاله اول: شبکه های عصبی عمیق با عمق تصادفی
شبکه های عصبی عمیق با بیش از صد لایه تاثیر به سزایی در کاهش نرخ خطا در سایر رقابت ها داشته اند . هر چند شبکه های عمیق تر باعث افزایش دقت میشود اما چالش های خاص خودشان را دارند. به عنوان مثال گرادیان میتواند ناپدید شود، زمان آموزش افزایش پیدا میکند و …
هدف این مقاله کاهش زمان آموزش با آموزش دادن شبکه های کوچکتر و استفاده از شبکه عمیق در زمان آموزش است . برای رسیدن به این هدف آنها متدی را به نام شبکه های عصبی با عمق تصادفی ارایه دادند.
در این مقاله ابتدا آنها کار را با یک شبکه عمیق شروع میکنند و در زمان آموزش در هر mini-batch تعدادی از لایه های شبکه را به صورت تصادفی حذف میکنند و آنها را توسط تابع همانی (در ریاضی یک تابع را همانی گویند هرگاه، همواره مقدار خروجی آن با ورودی برابر باشد، و اگر بخواهیم آن را به صورت یک معادله بنویسیم به صورت f(x) = x خواهد بود.) پشت سر میگذارد.
با استفاده از این متد زمان به صورت اساسی کاهش و دقت آزماش افزایش پیدا میکند. همچنین با استفاده از این متد میتوان عمق شبکه های residual را به بیش از 1200 لایه افزایش داد و همچنان دقت آزمایش را به صورت معناداری افزایش داد.
در شبکه های عصبی بزرگ به علت زیاد بودن تعداد نود ها گاها مشاهده میشود که تعدادی از نرون ها رفتار یک دیگر را کپی میکنند که این امر باعث بیش برارزش شدن شبکه میشود ، یکی از روشهایی که برای جلوگیری از بیش برارزش شدن شبکه استفاده میشود Dropout است که توسط جف هینتون و دیگران معرفی شد. ایده به این صورت است که در فاز آموزش تعدادی از نودها به همراه ارتباطات آنها به صورت تصادفی بیرون انداخته میشوند .
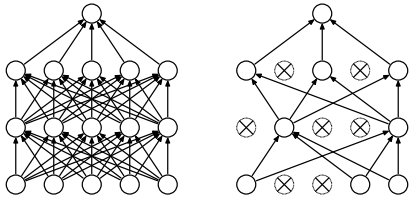
(سمت چپ) شبکه عصبی استاندارد ،(شکل سمت راست) شبکه عصبی بعد از اعمال عملیات بیش برارزش
در هر گام آموزش ما به صورت تصادقی و موقت درصدی ار نرون های لایه های پنهان به جزه نرون های لایه های ورودی و خروجی را حذف میکنیم ( معمولا 50% نرون ها شامل این پروسه میشوند).بعد حذف این نرون ها حجم شبکه کاهش پیدا میکند و شبکه توسط نرون های باقیمانده آموزش داده میشود . در ادامه بعد از بروز رسانی مقایر وزن ها و بایاس ها نرون های که از چرخه آموزش بیرون انداخته شده به شبکه باز میگردند و مجددا گروه جدیدی از نرون ها از شبکه بیرون انداخته میشوند . با این تکنیک داده های ورودی در هر گام آموزش بر روی یک شبکه با معماری متفاوت آموزش داده میشوند . این شبکه ها به روش های مختلفی بیش برارزش میشوند اما در انتها بدلیل اینکه نرون ها رفتار یک دیگر را کپی نمیکنند در هنگام رویارویی شبکه با داده های جدید بیش برارزش کاهش پیدا میکند. به عبارت ساده تر با این مکانیسم نرون ها مجبور میشوند که به یک دیگر در استخراج ویژگی ها تکیه نکند و هر زیر مجموعه از نرون ها قابلیت کلاسه بندی داده ها را داشته باشند.
مادامی که حذف تصادفی نود های شبکه(Dropout) منجر به کوچک تر شدن شبکه به صورت افقی میشود، این متد باعث کاهش شبکه در مسیر عمودی میشود. در سال های اخیر گرایش بیشتر محقیق داده به افزایش تعداد لایه های برای افزایش دقت بوده است اما شبکه های خیلی عمق مشکلات ذیر را دارند:
نادید شدن گرادیان : این یکی از مشکلات عمده شبکه های عصبی خیلی عمیق است . در فرآیند آموزش گرادیان خروجی شبکه نسبت به پارامتر های موجود در لایه های ابتدایی بسیار کوچک میشود که باعث کند شدن آموزش یا متوقف شدن آن میشود . متد های زیادی برای کاهش تاثیر آن در عمل وجود دارند، به عنوان مثال careful initialization, hidden layer supervision, Batch Normalization
کاهش استفاده مجدد از ویژگی ها : این مشکل در واقع مشابه مشکل قبلی است با این تفاوت که در انتشار رو به جلو اتفاق می افتد. ویژگی هایی که در لایه هایی ابتدایی محاسبه شده اند با ضرب در تعداد زیادی از وزن ها در لایه های میانی از بین میروند.
آفزایش زمان آموزش شبکه با عمقتر شدن شبکه : زمان Forward pass و backward pass به صورت خطی با افزایش عمق شبکه افزایش پیدا میکنند. حتی در یک کامپیوتر مدرن امروزی یا چندین GPU پیشرفته مدلی 152 لایه ای ResNet نیاز به چند هفته برای آموزش بر روی پایگاه داده Imagenet دارد.
شبکه های عصبی عمیق Residual
شبکه عصبی عمیق Residual یکی از جذاب ترین شبکه هایی است که اولین بار توسط تعدادی از محققین مؤسسه تحقیقاتی مایکروسافت ارایه شد.این مدل در رقابت ILSVRC 2015 در جایگاه اول قرار گرفت.شبکه ای که توسط این محققین ارایه شد شامل 152 لایه بود و نسبت به شبکه VGG 8 بار عمیق تر بود. به قول Jurgen Schmidhuber این شبکه مشابه یک شبکه LSTM بدون گیت است . اگر شما به شکل زیر (یک نود LSTM توجه کنید این گفته دقیق به نظر میرسد!
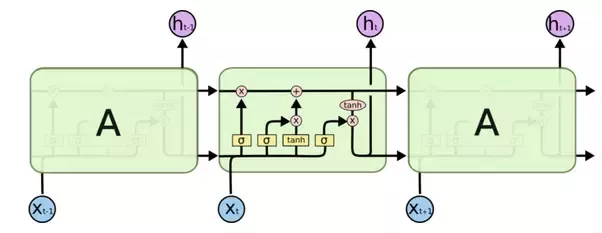
به عبارت دیگر ورودی های یک لایه پایین تر برای لایه های بعدی قابل دسترس است و تفاوت آنها این است که شبکه Residual مایکروسافت هنگامی بر روی عکس اعمال میشود از لایه های کانولوشن در ساختار خودش استفاده میکند.
ایده اصلی یک بلاک residual این است که ودودی توسط یک بلاک کانولوشن(مجموعه ای از توابع فعال ساز ، کانولوشن ، batch normalization) پردازش میشود ، نتیجه این تبدیلات یک تابع F(x) تولید میکند . نتیجه این تابع با ورودی لایه قبل جمع میشود . نویسنده مقاله اعتقاد دارد بهینه سازی بلاک residual نسبت به از معماری های قبلی ساده تر است از طرفی این ساختار به ما این امکان را میدهد که شبکه هایی با تعداد لایه های بسیار بیشتر بدون نگرانی از دست دادن گرادیان را ایجاد کنیم .
یکی از مشکلات عمده شبکه های کانولوشن سنتی این است که با افزایش تعداد لایه ها گرادیان لایه های ابتدایی ناپدید میشود اما این شبکه این مشکل را به ساده ترین شکل ممکن حل میکند. در یک شبکه سنتی تابع فعال ساز در یک لایه به صورت y = f(x) تعریف میشود. بطوریکه f(x) مجموعه بلاک کانولوشن ما است. در فرآیند آموزش هنکامی که در حال بروز رسانی پارامتر ها هستیم، گرادیان همیشه از میان تابع f(x) عبور میکند که به علت اعمال تبدیلات غیر خطی میتواند مشکل ساز شود. در شبکه ResNet این تابع به این شکل میباشد: y = f(x) + x
عبارت +x در انتهای این این معادله در واقع یک میانبر است . این عبارت به گرادیان این اجازه را میدهد که به صورت مستقیم از آن عبور کند. با سوار کردن این لایه ها بر روی یک دیگر گرادیان میتواند به عبارتی از روی این لایه ها بدودن ناپدید شدن پرش کند و به لایه های ابتدایی برسد .
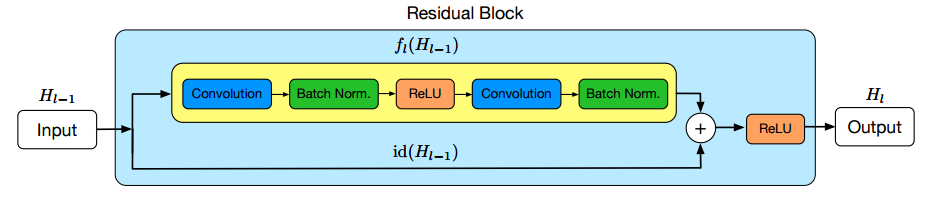
در شکل بالا Hl−1 ورودی لایه ، Hl خروجی، id تابع همانی و fl شامل مجموعه عملیات موجود در بلاک کانولوشن است.
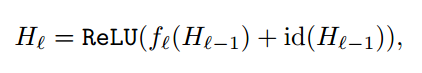
شبکه های عصبی عمیق با عمق تصادفی
ایده این مقاله در واقع مشابه عملیات Dropout است که در ابتدای پست توضیح داده شد. در این متد تعدادی از لایه ها به صورت تصادفی در هر minibatch حذف میشود.
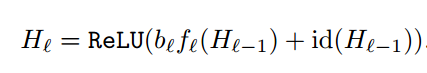
این معادله کاملا مشابه معادله قبلی است با این تفاوت که عبارت جدید با نام b(l) به آن اضافه شده است.این عبارت متغیر تصادفی برنولی است که مشخص میکند آیا ResBlock فعال یا غیر فعال است . اینکه از لایه residual استفاده شود یا از آن پرش کنیم توسط احتمال بقا pl تصمیم گیری میشود که PL یک ابر پارامتر است.
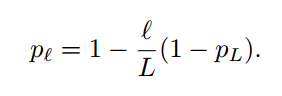
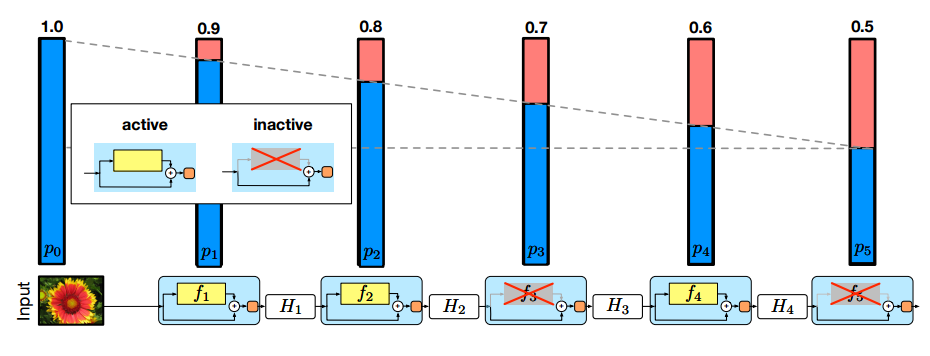
در شکل زیر میله های آبی و قرمز رنگ احتمال حذف لایه p(l) را نمایش میدهند که دو لایه 3 و 5 غیر فعال هستند.
در مقاله ذکر شده است در صورتی که مقدار ابر پارامتر pL=0.5 باشد زمان آموزش 25 درصد ، و در صورتی که pL=0.2 باشد زمان 40 درصد کاهش پیدا میکند. در فرآیند آزمایش مشابه Dropout از تمامی لایه ها استفاده میشود .
نتایج بر روی دیتاست CIFAR-10 نشان میدهد که نرخ خطا با این روش از 6.41 درصد به 5.23 درصد کاهش پیدا کرده است.سایر نتایج در مقاله ذکر شده است که شامل مقایسه زمان آموزش بر روی دیتاست های مختلف، نمودار آموزش و … میباشند که در این پست آورده نشده اند.
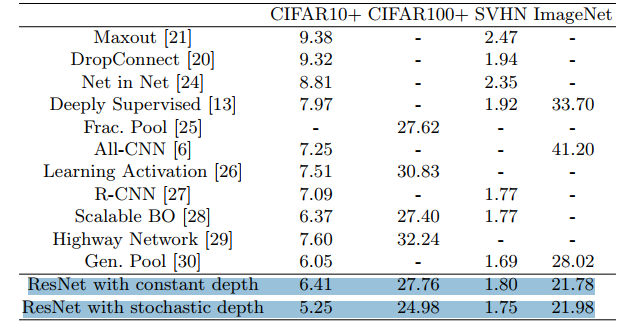
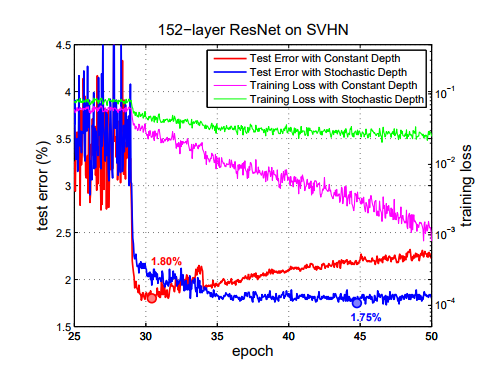
نتایج بدست آمده بر روی دیتا ست SVHN نشان میدهد که بدون استفاده از این متد شبکه در گام های ابتدایی بیش بر ارزش میشود ، در حالیکه با استفاده از این متد این مشکل حل میشود!
نتیجه گیری:
نتایج بدست آمده نشان میدهد که شبکه های عصبی با عمق تصادفی نه تنها سریع تر آموزش داده میشوند بلکه دقت بالاتری نسبت به مدل های با عمق ثابت دارند. در واقع این متد مثل dropout همانند یک regularization عمل میکند.کد این مقاله را میتوانید از لینک زیر دریافت کنید. دریافت کد