سال 2016 در یک نگاه- Pixel Recurrent Neural Networks-بخش چهارم
- RNN
- LSTM
- PixelCNN
- PixelRNN
پست امروز به generative models اختصاص دارد به همین منظور ابتدا یه سری مقدمه و تاریخچه را با هم مرور میکنیم ، سپس متدهای رایج را به صورت خلاصه بررسی خواهیم کرد و در انتها به بررسی مقاله PixelRNN خواهیم پرداخت که به عنوان بهترین مقاله ICML 2016 انتخاب شد.
تمامی محققین داده با این جمله موافق هستند که «آینده هوش مصنوعی به یادگیری الگوریتم های بدون نظارت تعلق دارد » مدل های generative شاخه ای ازتکنیک های یادگیری بدون نظارت هستند .مقدار فوق العاده زیادی اطلاعات در دنیای اطراف ما وجود دارند. به طور مثال ارتباطات مخابراتی هر ساله ۲۸ درصد افزایش پیدا میکند و حجم فضای ذخیره سازی ۲۳ درصد افزایش پیدا میکند ، این فقط بخشی ناچیز از اطلاعاتی است که در جهان هستی وجود دارد . بگذارید با یک مثال دیگر این موضوع را نشان دهم. اگر هر ستاره را به عنوان یک بیت داده در نظر بگیریم ، برای هر انسان به اندازه یک کهکشان اطلاعات وجود دارد ، که این حجم داده ۳۱۵ برابر تعداد سنگ ریزه های موجود در دنیا است ، اما این حجم اطلاعات هنوز کمتر از یک درصد اطلاعاتی است که در یک ملکول های DNA انسانها ذخیره شده است .

این مثال نشاندهنده حجم فوقالعاده عظیم اطلاعات است که در محیط پیرامون ما، چه در دنیای دیجیتال و چه در دنیای فیزیکی اتم ها وجود دارند و این داده ها به راحتی در دسترس هستند . اما بخش مشکل، ایجاد الگوریتم هایی است که بتوانند این گنجینه عظیم داده را تجزیه تحلیل و درک کنند .
مدل های generative یکی از امیدوار کننده ترین رویکردها برای رسیدن به این هدف هستند . برای آموزش مدل های generative ما ابتدا حجم عظیمی از اطلاعات در زمینه خاص ( شامل میلیون ها عکس، جملات ، صدا و …) را جمع آوری میکنیم و مدل ایجاد شده را بر روی این داده ها برای ایجاد داده هایی مشابه آموزش میدهیم . بینش اصلی پشت این رویکرد ، برگرفته شده از سخن معروف Richard Feynmanhttps://en.wikipedia.org/wiki/Richard_Feynman است که شاید در زمینه الگوریتم های هوشمند به این صورت ترجمه شود : اگرالگوریتم های یادگیری ماشینی بتوانند اطلاعات تولید کنند این امر میتواند به آنها کمک کند که داده ها را نیز درک کنند.(اطلاعات بیشتر در مورد این نقل قول معروف ایشان )

ترفند اصلی به این صورت است: شبکه های عصبی که ما از آنها به عنوان مدل های generative استفاده میکنیم تعداد پارامترهای به مراتب خیلی کمتری نسبت به داده های آموزش دارند ، بنابراین این مدل ها برای تولید مجبور هستند که ماهیت موثر درونی داده ها را کشف کنند.
فرض کنید ما یک مجموعه بزرگ از عکس ها مانند دیتا بیس ImageNet (1.2 میلیون) عکس داریم. عکس های موجود در این دیتابیس دارای اندازه متفاوتی هستند و در اکثر برنامه های کاربردی اندازه آنها به 256x256 تغییر میدهند این یعنی دیتابیس ما یک مجموعه بزرگ از 1,200,000x256x256x3 (حدود 200 گیگابایت) بلاک از پیکس ها است که تعدادی از آنها در تصویر زیر نمایش داده شده اند:

این عکس ها مثال هایی از محیط اطراف ما هستند که از آنها به عنوان “نمونه هایی از توزیع داده های حقیقی” یاد میشود. سپس ما یک مدل generative ایجاد میکنیم که توسط این داده ها آموزش داده میشود و وظیفه آن تولید عکس هایی مثل نمونه های موجود در دیتا بیس است. مدل ما میتواند یک شبکه عصبی بزرگ باشد که خروجی آن عکس هایی است که از آنها به عنوان “ نمونه های مدل “ یاد میشود. به عنوان مثال شبکه های عصبی عمیق کانولوشنال GAN (DCGANs) که توسط RadFord و همکارانش ارایه شد یکی از آن مدل ها است. این شبکه یک ورودی از 100 عدد تصادفی با یک توزیع یکنواخت پیوسته را از ورودی دریافت کرده و یک خروجی عکس با ابعاد 64 x64 x3 تولید میکند. با تغییر ورودی تصادفی ما خروجی تولید شده نیز تغییر میکند، که این تغییرات به نشان میدهد تا چه میزان شبکه ما ویژگی ها را یاد گرفته است. شبکه ای که در شکل زیر نمایش داده شده است از لایه هایی مثل لایه های Deconvolution و لایه های تماما متصل تشکیل شده است.
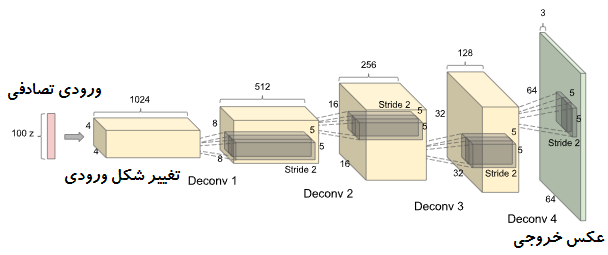
در ابتدا DCGAN توسط پارامتر های تصادفی مقدار دهی اولیه میشود در نتیجه عکسی که تولید میشود یک عکس کاملا تصادفی است، هرچند شبکه دارای میلیون ها پارامتر است که ما میتوانید مقادیر آنها را تنظیم کنیم و هدف شبکه تنظیم پارامتر ها به گونه ای است که بتوانند ورودی تصادفی را به شکلی تغییر دهد تا آن شبیه داده های آموزش شود، به عبارتی توزیع داده ها در مدل با توزیع داده های واقعی تطابق پیدا کند.در شکل زیر نمونه هایی از اتاق خواب های تولید شده توسط این شبکه نمایش داده شده است. هدف این پست بررسی این مقاله نمیباشد، این مقاله فقط نمونه ای از مدل های generative میباشد. تصاویر بیشتر و کد مقاله در این لینک موجود است)

دقت کنید در اینگونه مدل ها هدف ما ایجاد عکس هایی که دقیقا مشابه نمونه ها موجود در دیتا بیس هستند ، نیست بلکه تولید عکس هایی مشابه نمونه های واقعی است که فرآیند آموزش یکی از این مدل ها (GAN) را قبلا با هم بررسی کردیم . مقاله CAN-Creative Adversarial Networks
در شکل زیر نمونه ای از عکس های تولید شده توسط یک GAN به صورت Real-time نمایش داده شده است:

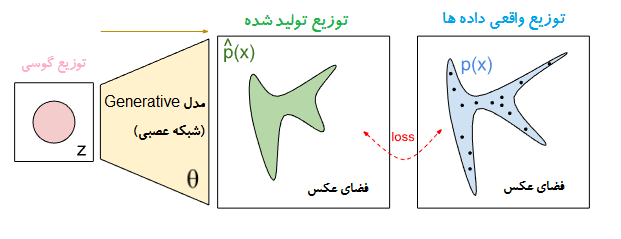
از دیدگاه ریاضی : در شکل زیر، توزیع واقعی داده ها با عنوان p(x) نماش داده شده است . قسمت آبی رنگ بخشی از فضای عکس را نمایش میدهد که به احتمال زیاد عکس های واقعی (دیتا بیس) در آن قرار گرفته اند و نقاط مشکی رنگ به محل واقعی نمونه های موجود در دیتا بیس اشاره دارند. ناحیه سبز رنگ به توزیع مدل اشاره دارد که این ناحیه نقاط خود را از یک توزیع گوسی که توسط یک شبکه عصبی نگاشت داده میشوند، میگیرد. شبکه یک تابع با θ پارامتر است . هدف شبکه پیدا کردن θ هایی است که منجر به ایجاد یک توزیع میشوند، این توزیع مشابه توزیع واقعی داده است. در نتیجه شما تصور کنید که ناحیه سبز رنگ در ابتدا بخش بزرگی از فضای عکس را در بر میگیرد و به مرور زمان این توزیع به توزیع آبی رنگ نزدیک و نزدیک تر میشود.
سه متد رایج برای مدل های generative وجود دارد که تمامی آنها دارای اصول مشابهی هستند اما در جزییات با یکدیگر متفاوت هستند:
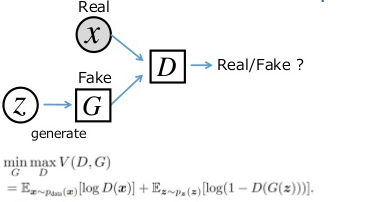
اولین مدل Generative Adversarial Networks (GANs) هستند که قبلا به آنها پرداختیم ، به صورت خلاصه این شبکه در واقع چیزی شبیه بازی minimax است که دو شبکه Generator و Discriminator شرکت کننده گان اصلی آن هستند (مینیماکس یک قانون تصمیم گیری است که در نظریهٔ بازیها و آمار برای مینیمم کردن احتمال شکست و ضرر در بدترین حالت که بیشترین احتمال ضرر را دارد از آن استفاده میشود) که شبکه discriminator سعی میکند که داده هایی که از توزیع حقیقی داده ها p(x) یا از p^(x) میآیند را کلاسه بندی کند. هر گاه شبکه discriminator متوجه تفاوتی بین این دو توزیع میشود شبکه generator مقادیر پارامتر های خود را کمی تنظیم میکند این فرآیند تا جایی ادامه دارد که داده های تولید شده توسط generator مشابه توزیع حقیقی داده ها شود و شبکه discriminator نتواند تفاوت بین آنها را حدس بزند.
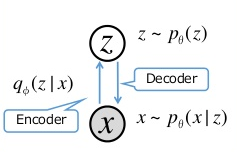
دومین مدل Variational Autoencoders (VAEs) هستند،در این رویکرد مسئله تولید محتوا به یک مدل گرافیکی یا مدل گرافیکی احتمالاتی تبدیل میشود (یک مدل احتمالاتی است که بیانگر ساختار وابستگی شرطی بین متغیرهای تصادفی توسط یک گراف است) که هدف آن ماکسیم کردن کرانه پایین لگاریتم درست نمایی است. به عبارت ساده ابتدا ورودی ما به یک بردار با ابعاد کمتر از ورودی فشرده میشود و سپس توسط چندین لایه شبکه عصبی به اندازه اولیه آن باز میگردد. این مدل ها برای ایجاد مجدد ورودی های خود آموزش داده میشوند که یه جوارایی شبیه یادگیری یک الگوریتم فشرده سازی برای یک دیتا بیس خاص است.
سومین مدل،مدل های Autoregressive (خود همبسته) هستند، و مقاله مورد بحث امروز ما از این متد استفاده میکند. مدل هایی از قبیل PixelRNN شبکه ای را آموزش میدهند که توزیع احتمال شرطی هر پیکسل با توجه به پیکسل داده شده قبلی را مدل میکند. این متد دقیقا مشابه متد char-cnn که در وبلاگ Andrej Karpathy با جزییات به آن پرداخته شده است با این تفاوت به جای پردازش داده ها در یک بعد، ما داده های عکس را به این الگوریتم میدهیم و شبکه عصبی بازگشتی ما این داده ها را در دو مسیر عمودی و افقی پردازش میکند در صورتی که در char-cnn داده ها، کاراکتر های یک دنباله 1 بعدی هستند.
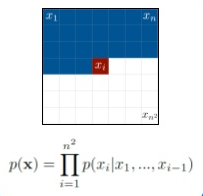
تمامی این متد ها مزایا و معایب خودشان را دارند. به عنوان مثال، عکس های تولید شده توسط VAEs کمی بلور هستند. GANs هر چند وضح ترین عکس ها را تولید میکنند اما بهینه سازی آنها به علت دینامیک آموزش ناپیدار آنها سخت است.
**اما چرا RNN ؟ **
در پست قبلی نشان دادیم که RNNs برای پیش بینی سری های زمانی با وابستگی بلند مدت عملکرد موثری دارند از طرفی در یک عکس ، به طور کلی هر پیکسل به همه پیکسل های اطراف آن وابسته است ، بنابراین میتوان از RNNs برای تولید پیکسل ها در عکس استفاده کرد.
ترتیب های متفاوتی برای پیش بینی پیکسل ها در یک عکس وجود دارد اما این روش بایستی قبل از پیاده سازی الگوریتم انتخاب شود . در این مقاله ترتیبی که پیکسل ها در آن تولید میشوند توسط نویسندگان به صورت از بالا به پایین و چپ به راست انتخاب شده است .
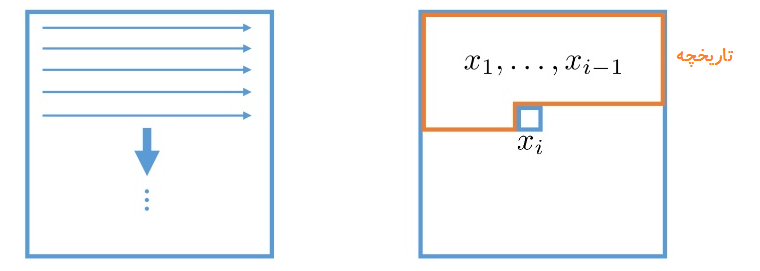
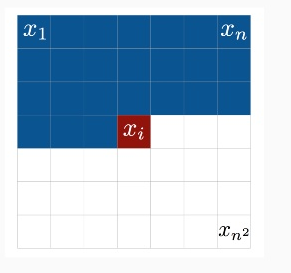
در معادله پایین p(x) نشان دهنده احتمال پیش بینی یک عکس که معادل ضرب احتمال شرطی xi پیکسل پیشبینی شده قبلی است .
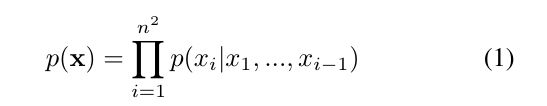
معادله بعدی احتمال پیش بینی مقادیر سه پیکسل RGB با توجه به xi پیکسل قبلی تولید شده نمایش داده شده است . در پیش بینی پیسکل xi ام مقادیر سه پیکسل R,G,B قبلی پیش بینی شده نیز مدنظر قرار داده میشود.
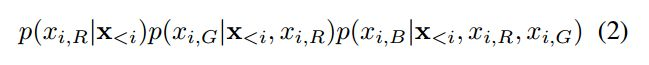
ترتیب پیش بینی سه مقدارRGB به صورت زیر است:
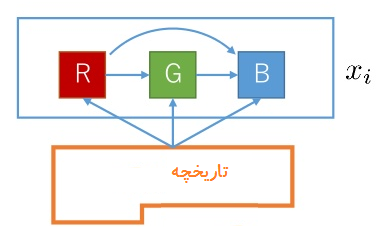
استفاده از لایه های LSTM
قبلاً از lstm ها برای تولید عکس استفاده شده بود اما مشکلی که وجود دارد این است که آنها این کار را پیکسل به پیکسل انجام میدهند و با توجه به تعداد زیاد پیکسل ها در عکس های یک دیتابیس زمان زیادی برای آموزش یک lstm نیاز است.
در یک lstm معمولی حالت پنهان پیکسل p(I,j) به حالت های پنهان پیکسل p(I,j-1) و p(I-1,j) وابسته است ، بنابراین تا زمانی که حالت پنهان پیکسل قبلی محاسبه نشده است نمیتوان حالت پنهان پیکسل p(I,j) را محاسبه کرد. این امر باعث میشود که نتوان حالت های پنهان را به صورت موازی محاسبه کرد در نتیجه هیچ صرفه جویی در فرآیند آموزش وجود ندارد .
در این مقاله برای کاهش زمان محاسبات از تکنیکی به نام Row LSTM استفاده شد .روش محاسبه حالت پنهان p(I,j) به صورت ذیر است :
p(i,j) = p(i-1,j-1), p(i-1,j+1), p(i-1,j), p(i,j)
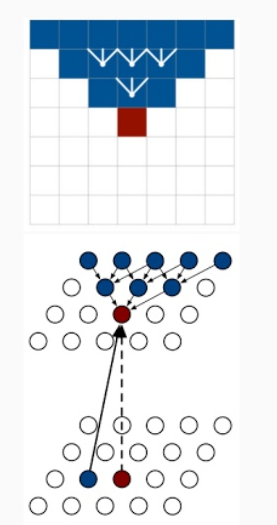
همانطور که در شکل بالا نشان داده شده است حالت پنهان یک پیکسل به صورت مستقیم به حالت های پنهان سه پیکسل بالای آن وابسته است و حالت پنهان سه پیکسل قبلی به صورت متناظر به حالت های پنهان پیکسل های بالای آنها وابسته است .در واقع در این تکنیک از این فضای مثلتی مانند برای پیشبینی پیکسل فعلی استفاده میشود . با توجه به اینکه حالت پنهان یک پیکسل فقط به سه پیکسل بالای آن وابسته است و هیچ گونه وابستگی به حالت عادی پنهان ردیف خودش ندارد ، در نتیجه میتوان حالت های پنهان یک ردیف را به صورت موازی محاسبه کرد که این امر باعث کاهش زمان محاسبات میشود .
هرچند این تکنیک مشکل پیچیدگی زمان آموزش lstm را حل میکند اما مشکل دیگری به نام از دست دادن محتوا وجود دارد بدین صورت که برای پیش بینی حالت پنهان یک پیکسل فقط از تاریخچه تعداد کمی از حالت عادی قبلی استفاده میشود که نتیجه دقیق نخواهد بود . برای حل این مشکل در این مقاله متدی به نام diagonal BLSTM یا LSTM دو طرفه قطری معرفی شد .
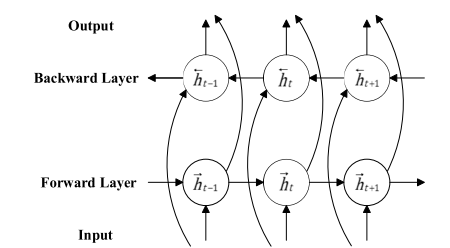
LSTM در هسته خود اطلاعات خود را از داده های ورودی که از میان حالت های پنهان شبکه عبور کرده اند میگیرد، به عبارتی در یک LSTM ساده شبکه فقط اطلاعات گذشته را یاد میگیرد زیرا ورودی های شبکه دریافت میکند مربوط به گذشته است. با استفاده از یک BLSTM میتوان اطلاعات ورودی را در دو مسیر پردازش کرد که یک مسیر از گذشته به آینده و مسیر دوم بر عکس است. با استفاده از این تکنیک در هر نقطه از زمان شبکه اطلاعات مربوط به آینده و گذشته را یاد میگیرد. به عنوان مثال فرض کنید در یک جمله ما میخواهیم کلمه بعدی در یک جمله را پیش بینی کنیم . در سطح بالا یک LSTM معمولی چیزی که میبیند جمله زیر است:
حمایت از کودکان ....
و شبکه سعی میکند کلمه بعدی را با توجه به این متن کامل کند. اما در یک ساختار BLSTM اطلاعاتی که شبکه میبیند به صورت زیر است:
Forward LSTM:
حمایت از کودکان ....
Backward LSTM:
.... را فراموش نکنیم!
کلمه مورد نظر “سرطانی”
همانطور که میبینید با استفاده از اطلاعات آینده، شبکه راحت تر میتواند کلمه بعدی را پیش بینی کند. شبکه های BLSTM کاربرد های فراوانی در NLP دارند به طوری که Christopher Manning در یکی از ارایه های خودشان در بروکلین ( با عنوان Representations for Language) گفتند:
ویدیوی کلاس در این لینک قابل دانلود است .
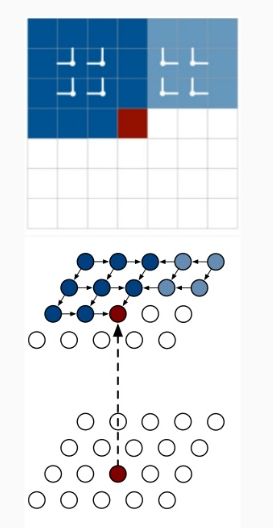
در این تکنیک همانطور که در شکل بالا نشان داده شده است حالت پنهان پیکسل p(I,j) به دو حالت پنهان p(I,j-1) و p(i-1,j) وابسته است. قبلا توضیح دادیم که BLSTM هر دو وابستگی Forward و Backward را پوشش میدهد،پس از تمامی پیکسهای تولید شده قبلی به عنوان تاریخچه برای پیش بینی مقدار پیکسل فعلی استفاده میشوند.
معماری دوم پیشنهاد شده در این مقاله معماری Pixel CNN است. دو متد و Diagonal LSTM میتواند بازه بزرگی از وابستگی در عکس ها را پوشش دهند اما یادگیری یک چنین بازه هایی به خاطر پیچیدگی طبیعت لایه های LSTM پرهزینه است. همانطور که میدانیم لایه های استاندارد کانولوشنال میتوانند محدوده ای از یک میدان دید را هدف قرار دهند و ویژگی پیکسل های این محدوده را به صورت همزمان پردازش کنند. از آنجایی که نگه داری اطلاعاتی مکانی اطلاعات عکس(پیکسل ها) در مدل های generative از اهمیت بالایی برخوردار است، از هیچ لایه Pooling در Pixel RNN استفاده نشده است.
در این معماری برای جلوگیری فیلتر کانولوشن از پیکسل های بعد از پیکسل فعلی برای پیش بینی پیکسل فعلی از یک متد به نام Masked Convolutions میشود. به عبارتی برای اینکه مطمین شویم که CNN ما فقط از اطلاعات پیکسل های بالا و سمت چپ پیکسل فعلی استفاده میکند فیلتر های ما نیاز است که ماسک دار شوند. این روش به شکل زیر است:
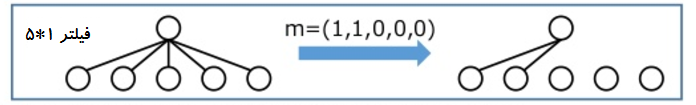
در شکل سمت راست یک فیلتر 5x1 نماش داده شده است و سمت راست فیلتر را بعد از اعمال ماسک نمایش داده شده است. فیلتر هایی که ورودی را به اولین حالت پنهان متصل میکنند در ماسک (1,1,0,0,0) ضرب میشوند. در این معماری از دو نوع ماسک A و B استفاده شده است که ماسک A فقط به اولین لایه کانولوشنال اعمال میشود که اتصالات را به پیکسل هایی که تاکنون پیش بینی شده اند محدود میکند(شکل بالا) و ماسک B در سایر لایه ها اعمال میشود.از آنجایی که در این معماری از لایه pooling استفاده نمیشود در نتیجه هیچ گونه عملیات نمونه افزایی(up-sampling) و نمونه کاهی (down-sampling) انجام نمیشود. با استفاده از ماسک Bخروجی کانولوشن شبکه سه کانال RGB را به عنوان ورودی خود دریافت میکند ، به عبارتی کانال های R,G و B برای پیکسل فعلی به صورت جداگانه پیش بینی میشوند. هنگام پیش بینی کانال R فقط پیکسل های سمت چپ و بالا میتوانند برای پیش بینی استفاده شوند اما زمان پیش بینی کانال سبز ، از مقدار کانال قرمز استفاده میشود و برای پیش بینی کانال سبز از مقادیر کانال های سبز و قرمز نیز استفاده میشود.
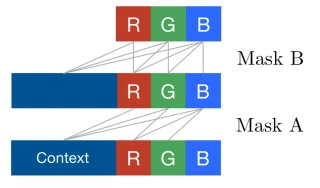
یکی از ضعف های این معماری مشکل نقطات کور آن است که این مشکل به علت اعمال ماسک به وجود میآید.برای شفاف تر شدن موضوع، آن را با یک انیمیشن ساده نمایش میدهم .

این مشکل در مقاله Gated PixelCNN بر طرف گردید که در آینده یک پست به آن اختصاص خواهم داد.کد این مقاله در این لینک موجود است. در شکل زیر نمونه ای از خروجی PixelRNN برای تکمیل چند عکس نمایش داده شده است.
