سال 2016 در یک نگاه-SqueezeNet-.بخش پنجم
- SqueezeNet
- AlexNet
- VGG
- NIN
یکی مشکل عمده شبکه های عصبی کانوشنال تعداد پارامتر های زیاد آنها است که این امر باعث افزایش مصرف حافظه میشود. مقاله امروز SqueezeNet نام دارد، معماری که به دقت مشابه معماری AlexNet ،با تعداد 50 برابر پارامتر کمتر دست پیدا کرد.(کمتر از 1 مگابایت)
شبکه های عصبی از قبل آموزش داده شده کانوشنال برای دستگاههایی مثل موبایل بسیار بزرگ هستند. به عنوان مثال حجم معماری AlexNet ، 240 مگابایت و معماری VGG16 بیش از 552 مگا بایت (مرجع ) است. شاید در مقایسه با فایل های ویدئویی که بر روی گوشی ذخیره میشوند ناچیز به نظر برسد اما تفاوت اساسی آنها در این است که شبکه در حال انجام محاسبات به صورت کامل بر روی حافظه بارگزاری میشود.
موضوعی که در مقاله Deep Compression (مقاله ای که به عنوان یکی از مقاله های برگزیده ICLR2016 انتخاب شد ) مطرح شده است جالب به نظر میرسد. در این مقاله از دو تکنیک Network Pruning و Trained Quantization and Weight Sharing برای فشرده سازی استفاده شده است که در نتیجه حجم AlexNet از 250 مگا بایت به 6.9 مگابایت بدون از دست دادن دقت، و حجم VGG16 از 552 مگابایت به 11.3 مگابایت نیز بدون از دست دادن دقت، کاهش پیدا میکند.
با توجه به وب سایت HowStuffWorks در پردازنده های چند هسته ای،حافظه پنهان (سطح یک ، دو و سه) ازStatic RAM ساخته شده اند. به صورت خلاصه در یک SRAM هر بیت که داده در آن ذخیره می شود از چهار یا شش عدد ترانزیستور تشکیل شده است که با یکدیگر تشکیل یک flip-flop را می دهند. اما DRAM به جای استفاده از ترانزیستور، از خازن برای نگهداری هر بیت داده بصورت جداگانه استفاده می کند. خازن ها زمانیکه شارژ می شوند دارای مقدار 1 هستند و زمانیکه شارژ ندارند به معنای عدد 0 هستند و این همان بیت هایی است که در آنها ذخیره سازی می شوند. با توجه به اینکه DRAM ها ارزانتر هستند از این نوع حافظه ها در حافظه اصلی در کامپیوترهای شخصی استفاده میشود. با توجه به سرعت بالای SRAM از این نوع حافظه ها در Cache پردازنده ها استفاده میشود.
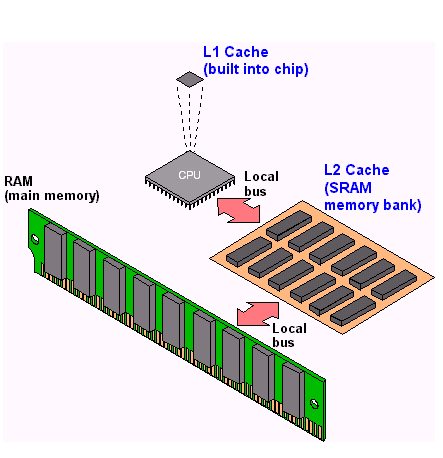
در تلفن های هوشمند امروزی حجم SRAM ها محدود است، از طرفی حافظه DRAM به عنوان یکی از مشارکت کننده های عمده مصرف انرژی در چنین دستگاههایی شناخته میشوند (با توجه به این مقاله DRAM power management and energy consumption ) . به عنوان مرجع، نویسندگان مقاله تخمین میزنند که برای اجرای یک شبکه عصبی با تعداد یک هزار میلیون کانکشن، حافظه DRAMبه تنهایی 12.8 وات انرژی مصرف میکند. از طرفی با توجه به حجم بالای این شبکه ها نمیتوان آنها را بر روی SRAM بارگزاری کرد.

بر گردیم به مقاله اصلی، در این مقاله از سه استراتژی برای کاهش تعداد پارامتر ها و افزایش دقت استفاده میشود که در نتیجه حجم شبکه به کمتر از یک مگابایت کاهش پیدا میکند.
جایگزین کردن فیلتر های 3x3با فیلتر های 1x1 :این استراتژی تعداد پارامتر ها را تا 1/9 کاهش میدهد .
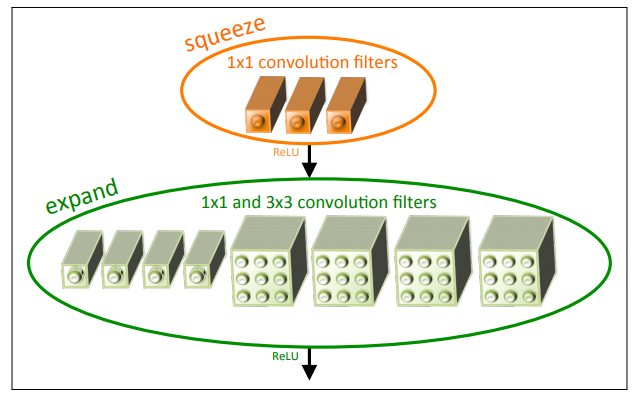
کاهش تعداد کانال های ورودی برای فیلتر های 3x3 باقیمانده : فرض کنید که یک لایه کانولوشن فقط از فیلتر های 3x3 تشکیل شده است . در این صورت تعداد کل پارامترهای این لایه (تعداد کانال ورودی * تعداد فیلتر ها*(3x3)) است. در یک شبکه عصبی کانولوشنال علاوه بر کاهش تعداد فیلتر های 3x3، کاهش تعداد کانال های ورودی نیز تاثیر به سزایی در کاسته شدن تعداد کلی پارامتر ها دارند. در این مقاله برای کاهش تعداد کانال های ورودی به فیلتر3x3 از لایه ای به نام squeeze استفاده میشود. این لایه ها در واقع از مجموعه ای فیلتر های 1x1 تشکیل شده اند.لایه دیگری که در این شبکه وجود دارد لایه expand است. این لایه ترکیبی از تعدادی فیلتر های3x3 و 1x1 است (شبیه معماری GoogleNet). نویسنده در مقاله مجموعه این دو لایه را بلاک Fire نام گذاری کرده است.
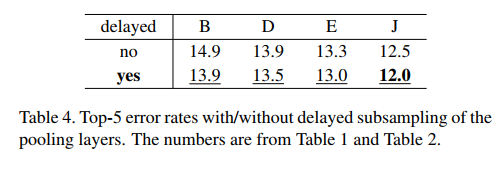
در یک شبکه کانوشنال هر لایه کانولوشن یک خروجی نگاشت فعال ساز (Activation map) با یک ابعاد خاص را تولید میکند که این ابعاد در کمترین حالت 1x1 است اما اغلب بیشتر از این مقدار است.طول و عرض این نگاشت های فعال ساز توسط دو پارامتر قابل کنترل است : اول، اندازه داده های ورودی (به عنوان مثال عکس های) 256x256 .دوم، انتخاب لایه هایی که عملیات نمونه کاهی (Downsampling) را انجام میدهند . به صورت رایج، این عملیات با طول اندازه یک در لایه های کانولوشن و Pooling یک شبکه عصبی کانولوشنال اعمال میشود.اگر لایه های ابتدایی در شبکه اندازه گام(Stride) زیادی را داشته باشند در نتیجه بیشتر لایه های شبکه نگاشت های فعال ساز کوچکی را تولید خواهند کرد. همینطور به طور برعکس، در صورتی که بیشتر لایه های شبکه اندازه گامی برابر 1 داشته باشند و از طول گام بیش از یک در لایه های انتهایی شبکه استفاده شود در این صورت بیشتر لایه های شبکه نگاشت های فعال ساز بزرگی خواهند داشت.نویسندگان این مقاله معتقد هستند که با کاهش اندازه گام در لایه های اولیه که به طبع باعث ایجاد نگاشت های فعال ساز بزرگتر میشود ،دقت خروجی افزایش پیدا میکند. این مدل نقطه برابر مدل هایی مثل VGG نت که در آن با نزدیک شدن به لایه های انتهایی نگاشت فعال ساز کوچکتر میشود، است.این متد به delayed down sampling معروف است که “شاید” برای اولین بار در مقاله Convolutional Neural Networks at Constrained Time Cost معرفی شد. در این مقاله نویسندگان این متد را در 4 معماری CNN اعمال کردند که در هر چهار مورد این متد باعث افزایش دقت کلاسه بندی شد.این مقاله نکات جالبی در مورد پیچیدگی زمانی عملیات کانولوشن و pooling و .. دارد که پیشنهاد میکنم آن را مطالعه کنید.
در شکل زیر سه نوع مختلف از این معماری نمایش داده شده است:
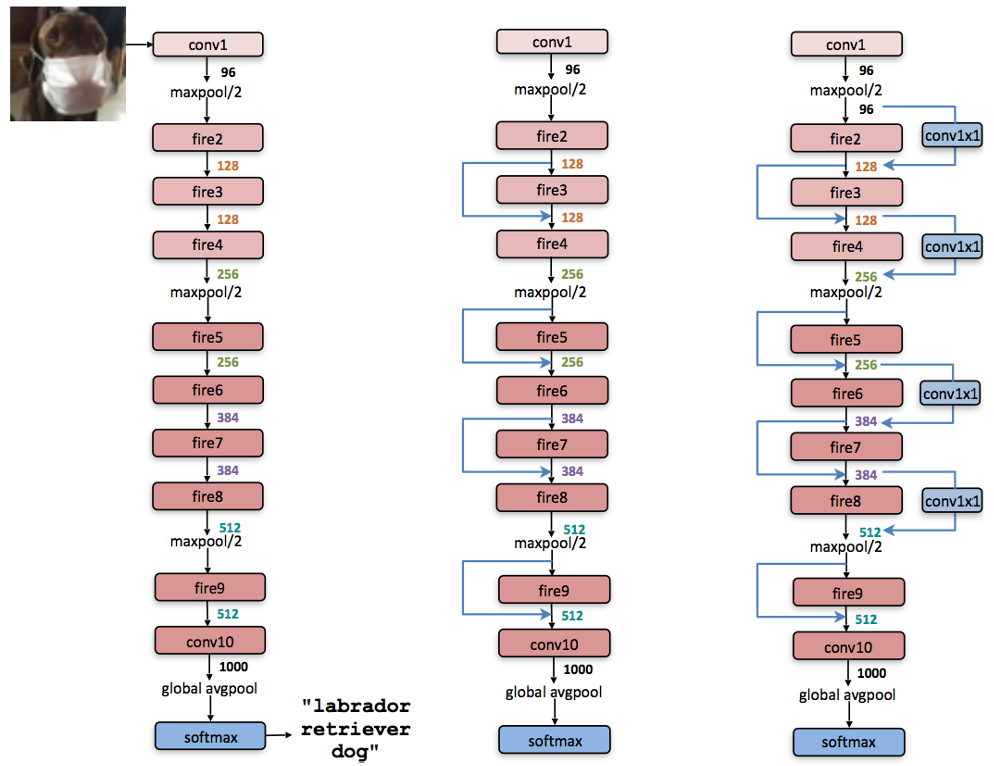
در شکل زیر خروجی SqueezeNet بعد از کامپایل شدن را به صورت انیمیش قرار دادم تا جزییات کاملا مشخص شود. همانگونه که در شکل زیر نمایش داده شده است بعد از ماژول نهم dropout با نسبت 50 درصد اعمال شده است . آموزش شبکه با نرخ یادگیری 0.04 شروع شده و به تدریج کاهش پیدا میکند. برای مطالعه جزییات بیشتر در مورد فرآیند آموزش (مواردی از قبیل اندازه batch و …) نسخه caffe کد در این لینک قرار گرفته است. در این شبکه از هیچ گونه لایه تماما متصلی همانند معماری NIN استفاده نشده است.
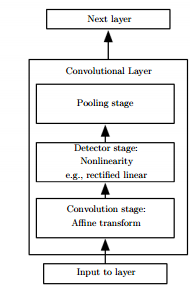
در مقالات مختلف یک بلاک کانولوشن به مجموعه ساختار ذیل اشاره دارد ، یک لایه کانولوشن در واقع ترکیبی از Pooling، کانولوشن و تابع فعال ساز است.
در معماری VGG تعداد پارامتر ها 133 میلیون است که بیش از 90 درصد این پارامتر ها در دو لایه تماما متصل این مدل قرار گرفته اند . این لایه ها عموما باعث بیش بر ارزش شدن شبکه میشوند . در NIN، Min Lin و همکارانش به جای استفاده از لایه های سنتی تماما متصل لایه از global average pooling استفاده کردند.
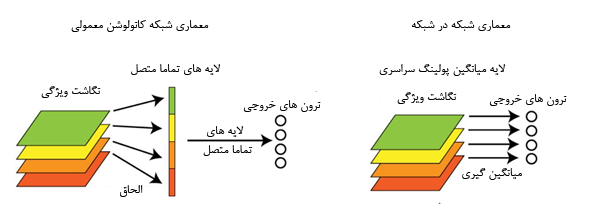
در این مقاله به جای استفاده از لایه تماما متصل سنتی آنها روشی به نام global average pooling را پیشنهاد دادند ، در شبکه هایی که از لایه تماما متصل برای کلاسهای بندی استفاده میکنند خروجی feature maps بعد از الحاق به یکدیگر به sofmax داده میشوند اما در این روش به ازای هر کلاس یک feature map بعد از آخرین لایه mlpcov تولید میشود به جای اضافه کردن یک لایه تماما متصل در بالای feature map ها آنها از feature map ها سود میبرند و نتایج بردار ویژگی مستقیما به softmax داده میشوند . یکی از ویژگی هایش این لایه نبودن مشکل بیش بر ارزش به علت عدم وجود پارامتری برای بهینه سازی است و از طرفی این لایه نسبت به تغییرات محلی مقاوم تر و با اصل شبکه هایش کانولوشن سازگارتر است.

در نگاه اول به نظر میرسد که ایده SqueezeNet همانند مطرح شده در ResNet و GoogleNet باشد. اما تفاوت عمده آنها چیست؟
این تفاوت ها را میتوان از سه دیدگاه بررسی کرد.دیدگاه اول “معماری”: همانند ماژول های Inception ماژول های Fire از تعدادی فیلتر با اندازه های متفاوت تشکیل شده است . به عنوان مثال مازول های Inception-v1 از تعدادی از فیلتر های 1x1،3x3 و 5x5 در کنار یکدیگر تشکیل شده اند. یک سوال اینجا مطرح است که چگونه یک شبکه عصبی کانولوشنال میتواند تصمیم میگیرد که چه تعداد از این فیلتر ها در هر ماژول وجود داشته باشد؟ در برخی از نسخه های Inception در هر ماژول بیش از 10 فیلتر وجود دارد که این تعداد فیلتر ها باعث بروز پدیده ای به نام انفجار ترکیبی میشود.
در ریاضیات انفجار ترکیبی یک مشکل اساسی در محاسبات است. به صورت خلاصه تعداد ترکیبات موجود برای حل یک مسله به صورت نمایی افزایش پیدا میکند، به صورتی که سریعترین کامپیوتر ها برای آزمودن آنها به زمان بسیار زیادی نیاز دارند. مشکل انفجار ترکیبی، توانایی کامپیوتر ها برای حل یک مسئله را محدود میکنند. به عنوان مثال فرض کنید که ما حق انتخاب n تصمیم گیری را داریم و برای هر تصمیم 10 گزینه وجود دارد. رو هم رفته شما 10 به توان n ترکیب از راه حل ها را پیش رو دارید. تعداد ترکیبات با افزایش n به صورت نمایی افزایش پیدا میکند!
اما در ماژول Fire، فقط 3 فیلتر وجود دارد. همانگونه که در بخش 5.3 مقاله بیان شده است در معماری GoogleNet،نویسنده گان از یک تعداد خاص فیلتر های 3x3 و 1x1 در هر ماژول بدون هیچ توضیحی و بیان علت استفاده میکنند. در این بخش نویسنده تحلیل جالبی در مورد تناسب بین فیلتر های 3x3 و 1x1 و تاثیر آن در اندازه مدل و دقت آن دارد. به گفته نویسنده در صورتی که در مدل ما 50 درصد فیلترها 1x1 و پنجاه درصد فیلترها3x3 باشند دقت خروجی مشابه مدلی با 99 درصد فیلتر 3x3 است، اما تفاوت فاحشی بین این دو مدل در اندازه و میزان محاسبات وجود دارد!
همانطور که در شکل بالا نمایش داده شده است نویسنده گان در این معماری از کانکشن های residual استفاده کرده اند که این امر باعث افزایش دقت خروجی شد.
GoogLeNet به دقت 87.3 درصدی دست میابد که حجم آن 53 مگابایت است. در این مقاله (بخش 5.2) نویسندگان مدلی را ارایه میدهند که به دقت 85.3 درصدی دست پیدا میکند که حجم آن ¼ GoogleNet یعنی 13 مگابایت است.