TPU چگونه کار میکند؟
- TPU
TPU یا واحد پردازش تنسور یک نوع مدارمجتمع با کاربرد خاص (Application-specific integrated circuit)هست که توسط گوگل به طور خاص برای کارهای یادگیری ماشین توسعه داده شد. در حال حاضر بسیاری از محصولات گوگل اعم از مترجم، دستیار جستجو ، جیمیل و … از این واحد های پردازش استفاده میکنند.
Cloud TPUمحیطی رو برای توسعه دهندگان و دانشمندان داده فراهم میکنه تا بتوانند محاسبات مدل های جدید و حجیم رو به آسانی توسط TPU انجام بدهند. همچنین در رویداد Google Cloud Next ‘18 نسخه 2 واحد پردازش تنسور نیز معرفی شد که در حال حاضر میتونید به صورت آزمایشیازش استفاده کنید.

اما سوالی که معمولا مطرح میشه اینه که تفاوت GPU،CPU و TPU در چیه؟ در این پست سعی میشه تفاوت این سه به صورت مختصر بیان شه.
یک شبکه عصبی چگونه کار میکنه؟
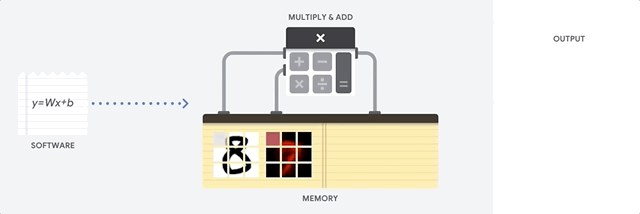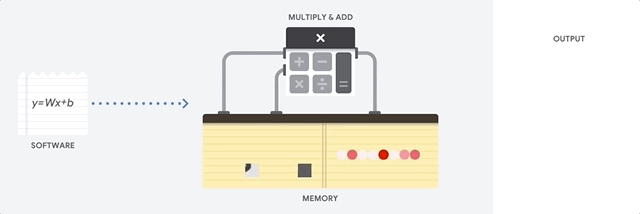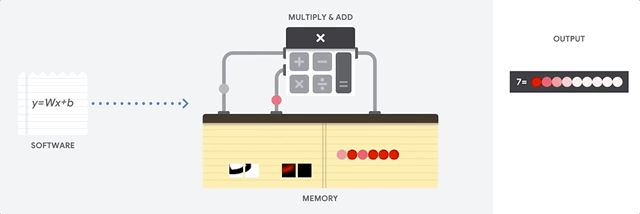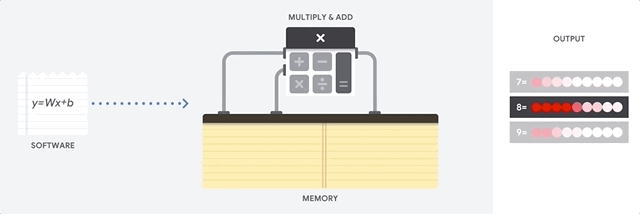
قبل از پرداختن به مقایسه CPU،GPU و TPU بیایید ببینیم چه نوع محاسباتی برای یادگیری ماشین، خصوصا شبکه های عصبی مورد نیازه؟ به عنوان یه مثال ساده ، تصور کنید ما از یه شبکه عصبی یک لایه برای شناسایی عکس یه رقم دست نویس که در دیاگرام زیر نمایش داده شده استفاده میکنیم:
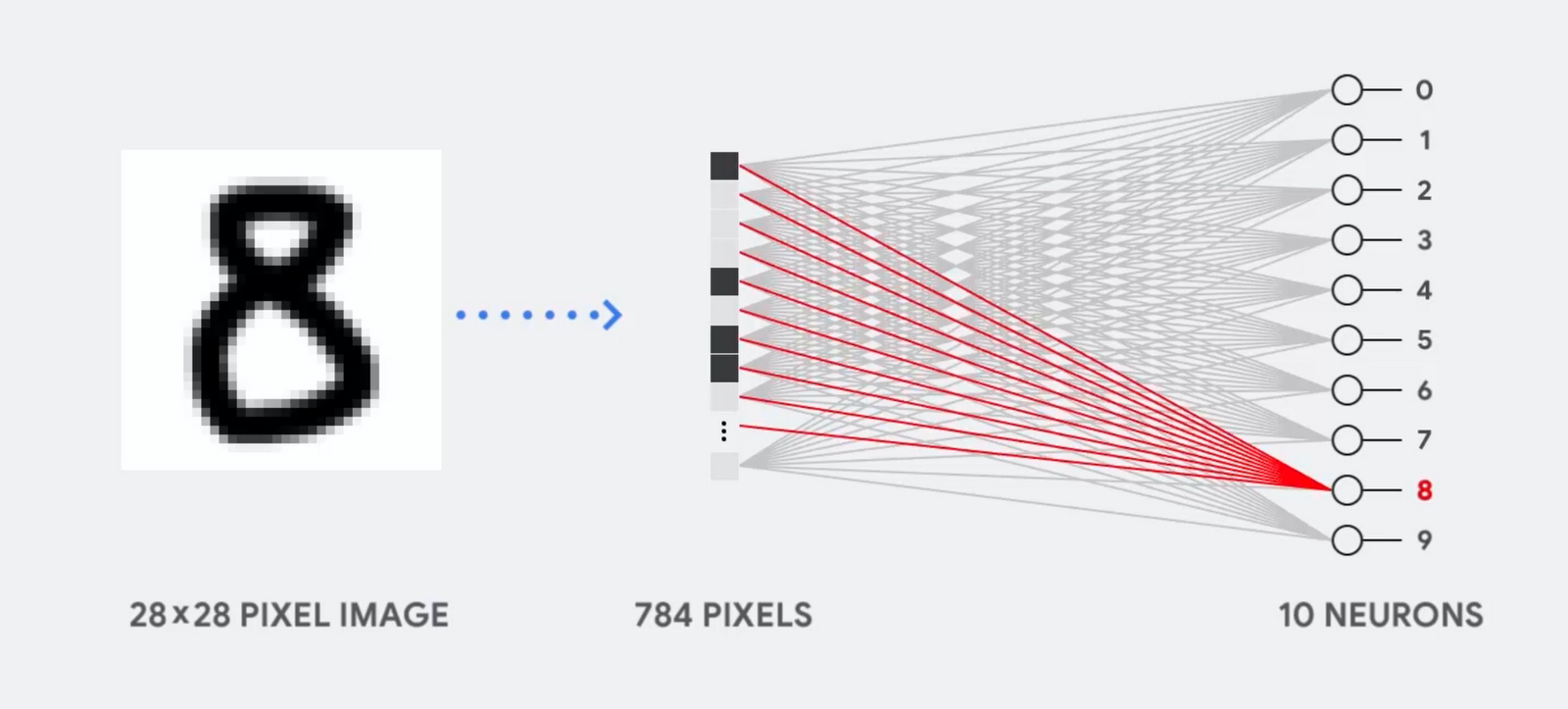
اگه این عکس(عدد 8) یک مشبک 28 در 28 پیکسل باشه، به راحتی میتونه به یک بردار با 784 مقدار (یک بردار 784 بعدی) تبدیل شه.نرونی که عدد “8” رو تشخیص میده ، این مقادیر را در وزن ها (خطوط قرمز) ضرب میکنه.وزن ها (Parameter)به عنوان یک فیلتر ویژگی ها را از دیتا(عکس) استخراج میکنند این وزن ها میزان شباهت بین عکس و شکل عدد 8 رو به ما میگه.

این ساده ترین توضیح طبقه بندی داده ها توسط شبکه عصبی هست، یعنی ضرب داده با پارامتر های متناظر و جمع اونها با هم.به طور خلاصه، شبکه های عصبی نیاز به مقادیر زیادی از این ضرب و جمع ها دارند. این عملیات به صورت ضرب ماتریسی سازماندهی میشن و هدف در اینجا پایین آوردن زمان محاسبات اجرای ضرب در ماترسی های بزرگ و پایین آوردن مصرف انرژی هست. به طور مثال در سال 2017 یکی از نشانه های پیشرفت یادگیری ماشین AlphaGo بود که تونست بهترین بازیکن GO رو شکست بده، هر چند AlphaGo بدون هیچ دانشی در این بازی استاد شد اما آموزش چنین الگوریتمی همانند یک استاد GO هزینه هایی در پی داره. تخمین زده میشه، هزینه انرژی مصرفی برای آموزش این الگوریتم بیش از 35 میلیون دلار هست ، آره یعنی کلی پول!
CPU چگونه کار میکند؟
CPU یک پردازنده همه منظوره بر اساس معماری فون نویمان هست.( یه مدل طراحی برای یک رایانهٔ ارقامیه که از یک واحد پردازش مرکزی و یک حافظهٔ مجزا مستقل برای نگهداری از اطلاعات و دستورالعملها استفاده میکنه)
بزرگترین مزیت CPU انعطاف پذیری اونه . با معماری فون نویمان ، میتونید هر نوع برنامه کاربردی رو اجرا کنید. مثلا میتونید از CPU در یک رایانه خانگی برای پردازش متن ، کنترل موتور راکت، انجام تراکنش های بانکی یا طبقه بندی عکس ها توسط یک شبکه عصبی استفاده کنید. اما این انطاف پذیری بیش از حد CPU باعث میشه ، سخت افزار همیشه متوجه این موضوع نشه که محاسبات بعدی چیه ، تا زمانی دستورالعمل بعدی توسط نرم افزار خوانده شه . بعد از اجرای هر محاسبات CPU مجبوره که نتیجه اون رو در حافظه نهان خودش (L1 cache) ذخیره کنه.این داستان دسترسی به حافظه در واقع معضل معماری CPU هست که بهش گلوگاه فون نویمان میگن. وقتی CPU با حجم پردازش زیاد یک شبکه عصبی در مقیاس بزرگ روبرو میشه ، هر کدوم از واحد های محاسبه و منطق (ALU)(بخشی از CPU که عملیات ضرب و تقسیم رو انجام میده) این عملیات رو یکی بعد از دیگری اجرا میکنه ، در هر گام نتایج بایستی به حافظه منتقل شه ، این یعنی محدود شدن تعداد محاسبات در هر لحظه،پایین اومدن بازدهی و بالارفتن هزینه انرژی مصرفی.
GPU چگونه کار میکند؟
برای بالابردن بازدهی ، GPU یه استراتژی ساده رو بکار میگیره: چرا تعداد واحد های محاسبه و منطق رو افزایش ندیم؟ GPUهای امروزی معمولا 2500 تا 5000 تا واحد محاسبه و منطق در یک پردازنده دارند به این معنی که شما میتونید در لحظه هزاران عملیات ضرب ماتریسی و جمع رو به صورت همزمان انجام بدید.

معماری GPU در برنامه های کاربری که نیاز به موازی سازی حجم دارند (مثل عملیات ضرب در یک شبکه عصبی) خوب کار میکنه. دلیل اینکه GPU امروزه در بین محققین داده محبوب شده، سرعت بالای اون در پردازش این محاسبات هست.
اما GPU همانند CPU یک پردازنده عمومی هست که میلیون ها برنامه کاربری و نرم افزار رو پشتیبانی میکنه ، این ویژگی باعث میشه که دوباره برگریم سر خونه اول ، یعنی مشکل گلوگاه فون نویمان! برای هر محاسبات در هزاران واحد محاسبه و منطق ، کارت گرافیک مجبوره نتیجه محاسبات رو در حافظه مشترک ذخیره کنه. GPU محاسبات موازی بیشتری در هزاران واحد محاسبه و منطق خودش انجام میده ، این امر منجر میشه انرژی بیشتری برای دسترسی به حافظه هزینه شه.
TPU چگونه کار میکند؟
وقتی گوگل TPU رو به عنوان یک مدارمجتمع با کاربرد خاص ساخت، به این معنی که به جای ساخت یک پردازنده همه منظوره ، گوگل یک پردازنده ماترس مخصوص شبکه عصبی ساخت. TPU ها مثل CPU ها نمیتونن عملیاتی نظیر کنترل موتور راکت،انجام تراکنش های بانکی و … رو انجام بدهند اما میتونند به راحتی عملیات ضرب و جمع حجیم در شبکه های عصبی با سرعت بسیار بالاتر و مصرف انرژی بسیار پایین تری انجام بدهند.دلیل اصلیش هم کاهش اثر گلوگاه فون نویمان هست.از اونجا که وظیفه اصلی این پردانده پردازش ماتریسه، طراح سخت افزار TPU از تمامی عملیات پیش رو آگاه هست. در TPU از معماریآرایه سیستولی استفاده میشه.
یکی از پرکاربردترین معماریهایی که برای موازی سازی پردازش تصویردر سطح پایین استفاده میشه معماری سیستولیک هست و در اون واحدهای پردازشگر معمولا دارای ساختاری ثابت هستند (در اینجا فقط با عملیات ضرب و جمع سرو کار داریم) به عبارتی در هر پردازنده هزاران جمع کننده و ضرب کننده جاگذاری و به هم متصل شده که یک ماتریس بزرگ رو تشکیل میده.
اما این معماری آرایه سیستولی چگونه محاسبات شبکه عصبی رو انجام میده؟ در ابتدا TPU پارامتر ها رو از حافظه به ماترس جمع کننده و ضرب کننده انتقال میده.

سپس TPU داده رو از حافظه میخونه. با اجرای هر عملیات ضرب ، نتایج به ضرب ضرب کننده های (در همین حین عملیات جمع به صورت همزمان انجام میشه) بعدی منتقل میشه . در نتیجه خروجی جمع نتایج ضرب بین پارامتر ها و داده خواهد شد.در حین انجام عملیاتی با این حجم ، پردازنده هیچ نیازی به دسترسی به حافظه ندارد.
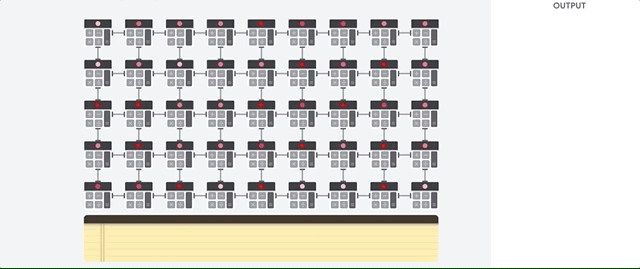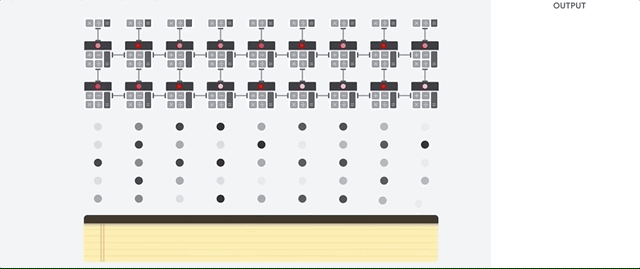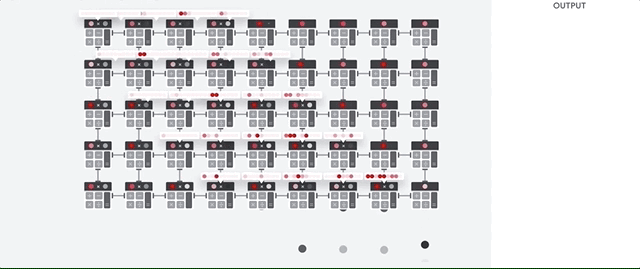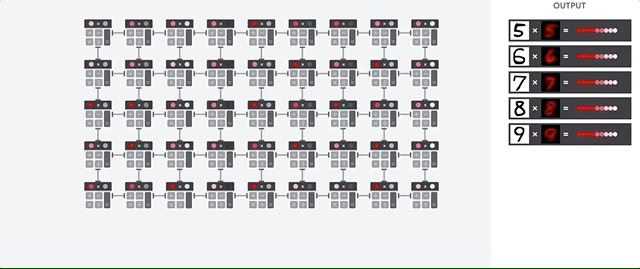
به این دلیله که TPU بازدهی بسیار بالاتر و مصرف انرژی بسیار کمتری نسبت به GPU داره. این خصوصیات باعث میشه که میزان هزینه به یک پنجم کاهش پیدا کنه.
منابع:
仅需1/5成本:TPU如何超越GPU,成为深度学习首选处理器