محدودیت های یادگیری ماشینی و مروری بر دیدگاه علی رحیمی و پرل
- NIPS
یکی از رایج ترین اعتراضاتی که در مورد هوش مصنوعی عمومی (AGI) می شنویم اینه که “AGI بد تعریف شده ، بنابراین شما واقعا نمیتوانید درباره آن حرف بزنید”
.چند دهه پیش، چند تن از دانشمندان پیشتاز هوش مصنوعی فکر میکردند اگر بتوان ماشین هوشمندی ساخت که بتواند انسان را در بازی شطرنج شکست دهد این ماشین قیاس خوبی برای AGI خواهد بود و میتوان به هسته هوش انسانی نفوذ کرد ، چیزی که آلن نیوول در این مقاله به صراحت قید کرده است.این مطلب رو نیز در کتاب هوش برتر نیک بوستروم خوندم.

موفقیت شگفت انگیز ماشین های راننده خودکار میتونه درس دیگری رو به ما بده! اگر من یه دانشمند هوش مصنوعی در دهه 1960 بودم، احتمالا فکر می کردم که یک ماشین خودکار که توانایی ماشین بدون راننده گوگل حال حاضر رو داره، میتونه همون AGI باشه! چون یک ماشین راننده خودکار باید در محیطی بسیار پیچیده، پویا و نا مشخص عمل کنه. همچنین (در موارد نادر) باید با معضلات واقعی اخلاقی مثل مسئله تراموا که یه آزمایش فکری مشهور در زمینه فلسفه اخلاق هست،مواجه شه. در عوض گوگل، ماشین راننده خوکار خود را با مجموعه ای از روش های چند دهه پیش ساخت که اصلا در باور من نمیگنجید! سوالی که به ذهنم خطور میکنه اینه آیا با ساخت راننده خودکار به AGI دست پیدا کردیم؟ خیر!
جفری هینتون میگه: ما باید از نو شروع کنیم. محققین هوش مصنوعی در یک نقطه مینیمم محلی گیر کرده اند! من به الگوریتم back-propagation مظنون هستم، دیدگاه من این هست که همه آن را دور بریزیم و از نو شروع کنیم. فکر نمیکنم مکانیسم یادگیری مغز اینگونه باشد.ما قطعا به این همه داده برچسب دار نیاز نداریم .
اگه NIPS 2017 رو دنبال میکردین، روز دوم این کنفرانس خیلی خبر ساز شد. وقتی داشتم ویدیوهای ارائه های این روز رو دنبال میکردم به صحبت های علی رحیمیبرخوردم. همون روز بود که یک استعاره جدید در باره یادگیری ماشینی متولد شد “کیمیا گری”! ویدئوی این کنفرانس رو در یوتیوب بار گزاری کردم و در فاصله کوتاهی دیدم که همه دارن دربارش صحبت میکنند.
نیمه اول صحبت های ایشون اختصاص داشت به مقاله ای که در 2007 با عنوان ویژگیهای تصادفی برای (به عنوان یه راهکار کارا برای طراحی) ماشین های کرنلِ بزرگ مقیاس منتشر کرد، این مقاله به این دلیل که بعد از 10 سال هنوز مهم هست جایزه “ Test of Time” رو برای ایشون برد. در این مقاله از تخمین های بر اساس ویژگیهای تصادفی فوری برای کاهش مشکل ماشین کرنل استفاده میشه. اینطور که من متوجه شدم در این مقاله نمونه های فضای هسته به یک فضای ویژگی تخمینـی بـا ابعـاد پـایینتر نگاشـت میشه و مـدلهای خطی ساده در فضای نگاشت شده بکار گرفته میشن.
در یادگری ماشین عبارت kernel بهحقه کرنل اشاره داره. حقه کرنل متدیه که از یک طبقه بندی خطی برای حل یک مسئله غیر خطی استفاده میشه. به عنوان مثال فرض کنید توزیع داده های ما تصادفی هست برای اینکه داده ها رو طبقه بندی کنیم، به کمک تابع ریاضی (Kernel function) اونها رو به یه فضای دیگر(بالاتر) نگاشت میدیم، که در اون فضا، داده ها تفکیک پذیر باشن
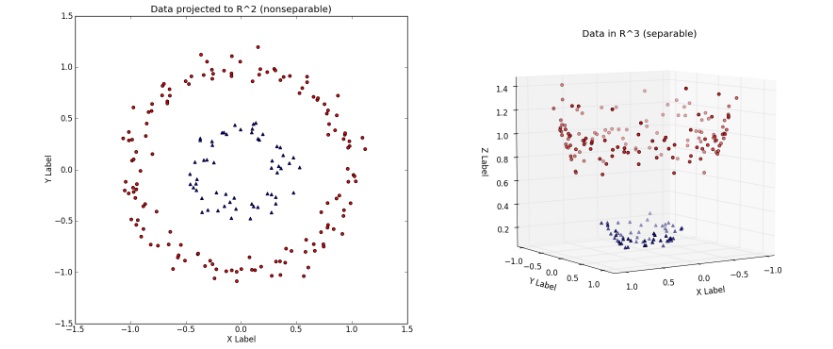
اما بریم سراغ بخش دوم صحبت های ایشون. در واقع ایرانیان با کیمیاگری هم ذات پنداری خاصی دارند، واژه ایست کاملا آشنا و قابل لمس. این دانش “کیمیاگری” از ایران برآمد. از دیرباز تبدیل مس به طلا و ساخت داروی جاودانگی که به آن اکسیر نیز گفته میشده، بیشترین تلاش کیمیاگران را به خود معطوف داشته. علی رحیمی،محققین یادگیری ماشینی را به کیمیا گران این دوره تشبیه میکنه، به این معنا ، وقتی ما یک مدل عمیق رو طراحی میکنیم ، هیچ ایده ای در مورد اینکه چندتا لایه بایستی به کار ببریم یا مدل ما چقدر پهن باید باشه، نداریم، روش تحلیلی خوبی که بتونه ما رو راهنمایی کنه وجود نداره. در نتیجه مدل های متععدی رو ایجاد میکنیم و بهترین اونها رو انتخاب میکنیم. در بعضی مواقع حتی یک مدل میتونه بهتر عمل کنه،چون در هنگام مقدار دهی اولیه تصادفی نقطه بهتری رو انتخاب کردیم! در مقالات مختلف ادعاهای مختلفی ارایه میشه اما ، به ندرت اثبات ریاضی خاصی ارائه میشه.چرا؟

به قول رحیمی:چیزی که امروزه به اون نیاز داریم یک تئوری محکم در این زمینه است.عدم وجود یک تئوری محکم و عدم وجود مدل های ذهنی سازماندهی شده در یادگیری عمیق ما رو به کیمیاگران این زمانه تبدیل کرده است.
دو شکل زیر رو در نظر بگیرید؛ یک تصویر مربوط به معماری VGG هست و دیگری مربوط به لنز دوربین. اگه بخوایم به صورت کلی بهشون نیگاه کنیم در نگاه اول هر دو شامل یه سری لایه هستند که ورودی رو به شکلی پردازش میکنند.
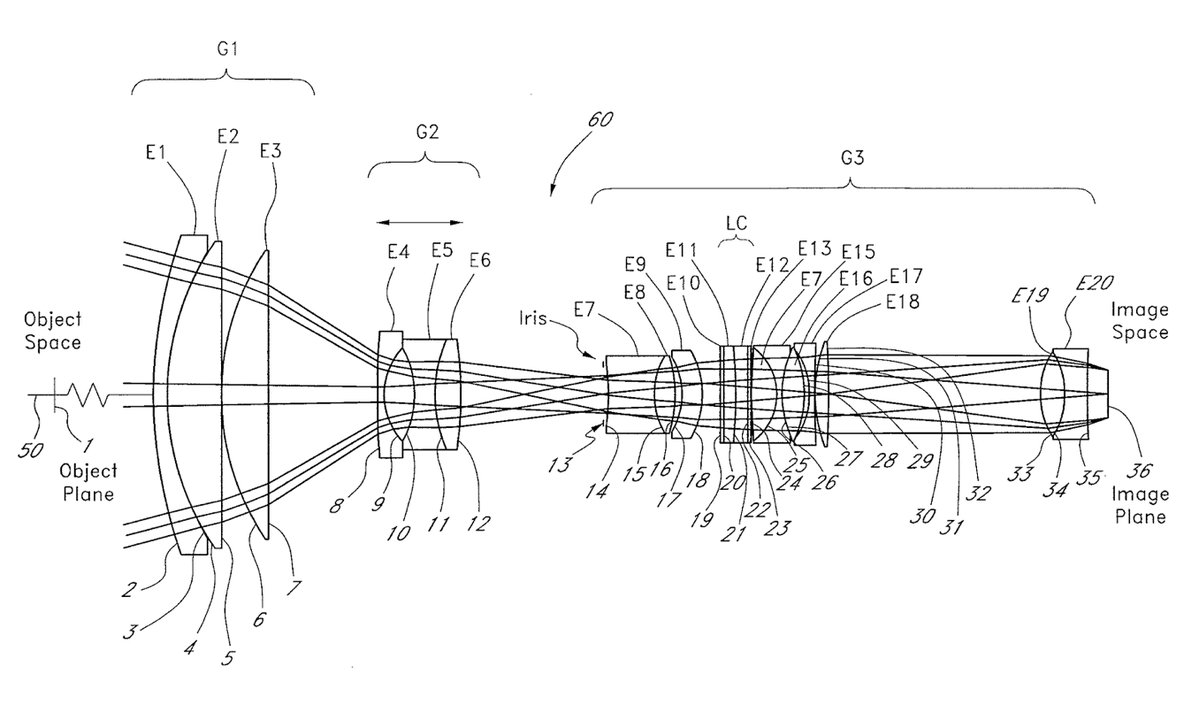
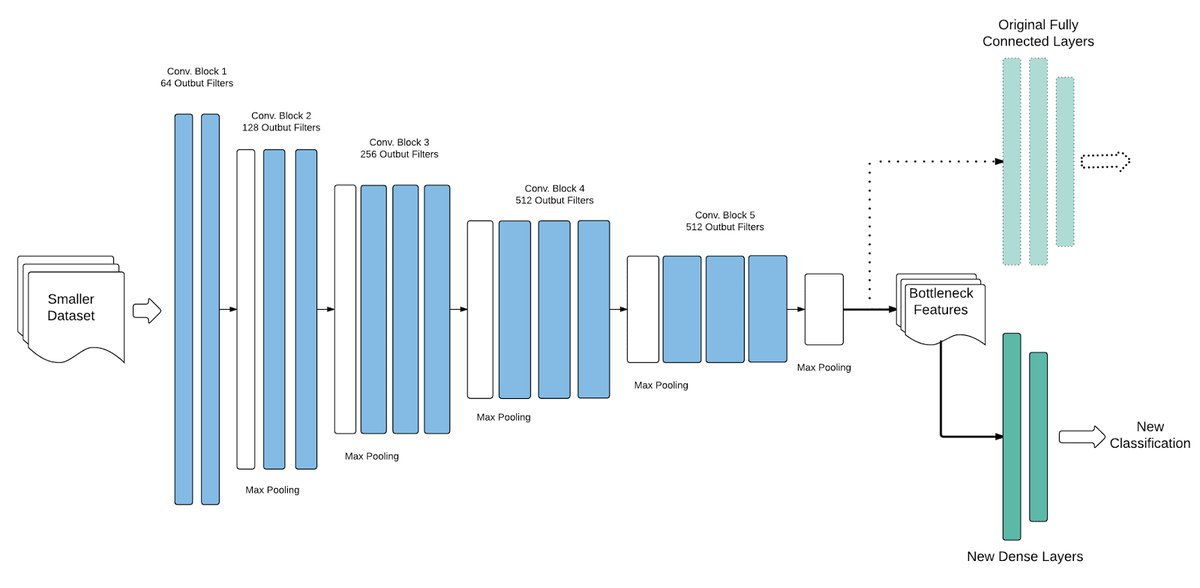
امروزه ما شبکه عصبی رو جعبه سیاه میدونیم اما در مورد لنز دوربین چنین تعبیری وجود نداره.دلیلش این نیست که مکانیسم نور ساده هست ، دلیلش اینه که مدل های ذهنی در نور خوب سازماندهی شدن. قیاسی که در این پست توسط ایشون ارایه شد.
علی رحیمی در ابتدا میگه: در اون سالها ترسی که بر محققین چیره شده بود،قوانین سخت گیرانه ای بود که توسط افرادی که اونها رو The NIPS Rigor Police (پلیس سختگیر NIPS) می نامه وضع شده بود.این افراد در میان پوسترهای تحقیقاتی پرسه میزدن و بیشترین استرس رو به محققین وارد میکردن .محققین بایستی برای تمامی جزییات کارشون تئوری قابل قبولی ارایه میدادن.
اما الان شرایط فرق کرده، این حوزه پیشرفت بسیار بالایی داشته. نتایج خیرهکنندهای بهدست میآوریم، به نظر میرسه که اتومبیلهای راننده خودکار به زودی تحقق پیدا میکنن، هوش مصنوعی میتونه چهره افراد را در عکسها تشخیص بده، ایمیلهای صوتی را به صورت متن درآوره، متون رو ترجمه کنه. شرکتهای میلیون دلاری بر پایه یادگیری ماشینی تأسیس شدن و از جهات مختلف، نسبت به ۱۰ سال پیش در موقعیت بهتری هستیم. اما در بعضی جهات، در موقعیت بدتری هستیم. احساس خوبی نسبت به خودمان داریم، جملاتی شبیه به این میگیم «یادگیری ماشینی الکتریسیته جدیده». من یک استعاره جایگزین پیشنهاد میکنم: یادگیری ماشینی تبدیل به کیمیا شده است. کیمیا خوبه، کیمیا بد نیست،کیمیا برای خودش جایگاهی داره، کیمیا جواب داد!

شیمیدانان متالورژی، روشهای داروسازی، تکنیکهای رنگآمیزی پارچه، و فرایندهای مدرن ساخت شیشه رو اختراع کردن . شیمیدانان بر این اعتقاد بودن که میتونن فلزهای پایه رو به طلا تبدیل کنن و زالوها روش خوبی برای درمان بیماریها بودن.
برای رسیدن به درک جدید از دنیایی که علوم فیزیک و شیمی سالهای ۱۷۰۰ میلادی به ما دادند، باید بیشتر نظریههای شیمیدانها را کنار میذاشتیم. اگر در حال ساختن سرویسهای بهاشتراکگذاری عکس هستید، کیمیا چیز خوبیه،اما امروزه در حال ساختن سیستمهایی برای مدیریت خدمات سلامت و مشارکت در بحثهای مدنی هستیم. من ترجیح میدم در دنیایی زندگی کنم که سیستمهای آن بر پایه دانش دقیق، قابل اعتماد، قابل تأیید ساخته شده باشن نه کیمیا. همانقدر که پلیس سختگیر NIPS ناراحتکننده بود، آرزو داشتم که برگرده.
اما بذارین براتون مثال بزنم، کیمیا گری کجاها به ما آسیب میرسونه:
اول SGD و اشکال مختلف اون
علی رحیمی میگه: شرط میبندم همه شما سعی کردین که یه شبکه عمیق رو از صفر آموزش بدین و برای اینکه نتونستید به نتایج خوبی برسید، احساس بدی پیدا کردین. فکر نمیکنم مقصر شما باشین. به نظر من مقصر gradient descent هست.
در ادامه مثالی رو ارایه میده که در اون یک شبکه عصبی دولایه با فعال ساز خطی رو توسط الگوریتم gradient descent آموزش میده ، یک شبکه دولایه با فعالسازهای خطی که در آن برچسبها یک تابع خطی نامناسبی از ورودی هستن. اگه میخواین این نتایج رو بررسی کنید، در این نوت بوککد قرار داده شده. نتایج نشون میدن که gradient descent در ابتدا به خوبی راه خودش رو پیدا میکنه اما بعد از یه مدت هیچ پیشرفت خاصی خاصی نداره، شاید بگین که در مینیمم محلی گیر کرده ، اما اینطور نیست چون گرادیان به سمت صفر کاهش پیدا نمیکنه، شاید هم بگین که به توازن نویز آماری (statistical noise floor) دیتا ست برخورده اما این هم نیست.میتونم امید ریاضی خطا رو حساب کنم و با gradient descent اون رو به حد اقل برسونم. همان اتفاق میفته، Gradient descent با نزدیک شدن به جواب خوب ، آهسته تر حرکت میکنه. این دقیقا همون اتفاقیه که در معماری مثل Inception اتفاق میفته، اگه تا به حال Inception را روی ImageNet آموزش داده باشین، خواهید دید که gradient descent، در چند ساعت خوب عمل میکنه اما بعد در ادامه وارد این نظام میشه و روزها طول میکشه که از اون عبور کنه.
نکته اینجاست که الگوریتم لونبرگ-مارکارد در این زمینه بهتر کار میکنه. شاید بگید که این یه مدل بچه گانست اما این دقیقا روشیه که از ما از اون برای کسب دانش استفاده میکنیم، ابتدا ابزار خودمون روی مسائل کوچک قابل تحلیل اعمال میکنیم ، و سپس به سمت پیچیدگی حرکت میکنیم. موارد متفاوتی وجود داره که واقعا درد ناک هستند. مثل باگهای متعددی که در فروم های مختلف مطرح میشن، اینکه چطور با جابه جا کردن ترتیب Batch Normalization (گذاشتن اون قبل یا بعد از Relu) نتایج تغییر میکنه.

دوم Batch Normalization
علی رحیمی میگه:Batch Normalization تکنیکیه که باعث تسریع همگرایی میشه ، اون رو بین لایه ها قرار میدین و gradient descent سریعتر عمل میکنه. به نظر من استفاده از تکنیکهایی که اونها رو نمیفهمیم مشکلی نداره. من دقیقاً نمیدونم یه هواپیما چطور کار میکنه و خودم از هواپیما برای رسیدن به این کنفرانس استفاده کردم. ولی آیا همیشه ساختن سیستم روی چیزهایی که به خوبی نمیشناسیم کار درستیه؟ این چیزیه که من در مورد علت خوب کار کردن بچ نرم میدونم.
ولی آیا نمیخواین بفهمید که چرا کاهش internal covariate shift، سرعت gradient descent رو افزایش میدهد؟(Covariate shift در واقع به تغییر توزیع ورودی در یک سیستم یادگیری اشاره داره، موضوع تغییر توزیع ورودی رو میشه علاوه بر کل سیستم به لایه های اون هم تعمیم داد، این کاریه که بچ نرم انجام میده. یعنی میتونیم در لایه های مختلف یک شبکه عمیق همون تغییر توزیع (ورودی) رو داشته باشیم .وقتی این اتفاق در سطحوح پایین (نورونها) رخ بده اصطلاحا بهش میگیم internal covariate shift رخ داده.) نمیخواین شواهدش رو ببینید و لمس کنید؟ Batch Norm تبدیل به یک عملیات بنیادی در یادگیری ماشینی شده، خیلی خوب کار میکنه اما تقریباً هیچی از اون نمیدونیم.
یودیا پرل، یکی از چهره های پیشرو در هوش مصنوعی میگه :” هوش مصنوعی برای یک دهه اخیر توی گل کرده “ ، و نسخه ایشون برای برون رفت از این شرایط آموزش درک “چرایی و علت” به ماشین هاست!

هوش مصنوعی ، بخش عظیمی از “هوشمندیش” رو مدیون یودیا پرل هست. در دهه 80 ، تلاش های ایشون باعث شد ماشین ها بتوانند به صورت احتمالی استدلال کنند و هم اکنون ایشان به یکی از منتقدین تند و تیز این زمینه تبدیل شده. در آخرین کتابشون The Book of Why“علم جدید علت و معلول” ، استدلال میکنه که هوش مصنوعی به علت درک ناقص ما از “ماهیت هوش” عاجز مانده است.چند ماه پیش، پرل مقاله ای در این زمینه در آرکایو منتشر کرد که به محدودیت های یادگیری ماشینی میپردازه.
Theoretical Impediments to Machine Learning With Seven Sparks from the causal revolution

سه دهه قبل، یک چالش اصلی در تحقیقات هوش مصنوعی ، برنامه ریزی کردن ماشین ها بود، به صورتی که بتواند یک عامل بالقوه را به مجموعه ای از شرایط قابل مشاهده ارتباط بدهند. پرل در اون زمان، طرحی به نام شبکه های بیزی رو ارایه داد. شبکه های بیزی این توانایی رو به یک رایانه دادند که بتونه با بررسی حالات یک بیمار ، نوع بیماری اون شخص رو پیش بینی کنه.” به عنوان مثال یک فرد بیمار که از آفریقا با تب و تنی کوفته برگشته، به احتمال زیاد مالاریا دارد.” در سال 2011 ، پرل برنده جایزه تورینگ که بالاترین افتخار در علوم رایانه هست، شد.(یکی از دلایل مهمی که باعث اعطاء این جایزه به ایشان شد ، طرح شبکه های بیزی بود).
به اعتقاد پرل، هوش مصنوعی در منجلاب وابستگی های احتمالی فرو رفته است. این روزها،رسانه ها آخرین پیشرفت ها و یافته های یادگیری ماشین و شبکه های عصبی را در بوق و کرنا میکنند ، مثلا کامپیوتر هایی که میتوانند در بازی GO استاد شوند یا کامپیوتر هایی که میتوانند راننده شوند، اما پرل زیاد تحت تاثیر قرار نگرفته. امروز، پیشرفته ترین فن آوری در هوش مصنوعی به ندرت نسخه ارتقا یافته از کارهایست که ماشین ها در یک نسل پیش میتوانستند انجام دهند، به عبارتی پیدا کردن نظم و قاعده پنهان در یک مجموعه بزرگ دادگان.
پرل میگه:تمامی دستاوردهای شگفت آور یادگیری عمیق فقط به برازش منحنی (عبور معادله های پیچیده از مجموعه نقاطی که همان داده های ما هستند) ختم میشود
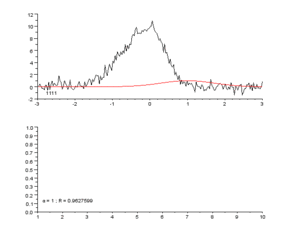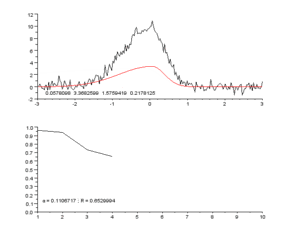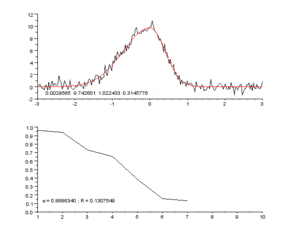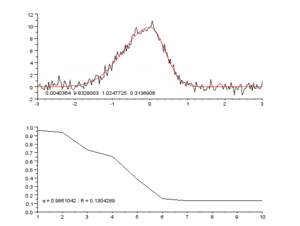
پرل در کتابش به طور مفصل یک چشم انداز برای اینکه “چگونه یک ماشین “(واقعا هوشمند) می اندیشد” ، ارایه میده . راه حلی که ارایه شده جایگزین کردن استدلال مبتنی بر تداعی(استدلال تداعی گرا: یادآوری ، همخوانی و همبستگی) با استدلال سببی هست.به جای داشتن تنها قابلیت همبسته کردن مالاریا با تب، ماشین ها نیاز به این توانایی دارند که استدلال کنند مالاریا باعث ایجاد تب میشود.وقتی بتونیم چنین چارچوب سببی رو بوجود بیاوریم ،این امکان ایجاد میشه که بتوان از ماشین، سوالات خلاف واقع پرسید (یک مثال خلاف واقع این جمله میتونه باشه:”اگر سگها گوش نداشتند،نمیتوانستند بشنوند” در این جمله بخش اول ، یک مثال خلاف واقع است چون سگ ها میتوانند بشنوند). به نظر پرل این سوالات خلاف واقع ، سنگ بنای اندیشه علمی است و برای اینکه این شکل از تفکر کردن امکان پذیر بشه ، یک نسخه قرن بیست و یکی از چارچوب بیزی “ که به ماشین ها این امکان رو میده به صورت احتمالی تفکر کنند “، پیشنهاد میده.
پرل فکر میکنه که استدلال سببی راه حل رسیدن به هوش مصنوعی در سطح انسان است. این هوش مصنوعی به طور موثرتری با انسان رابطه برقرار میکنه و حتی میتونه ظرفیت هایی برای اختیار در او بوجود بیاره.

یکی از دلایل نام گذاری این کتاب به BooK of Why به خلاصه کارهایی بر میگرده که ایشون در 25 سال اخیر در باره “علت و معلول” انجام داده اند ، اینکه چگونه ما انسانها به سوالاتی که به طور ذاتی سببی هستند، پاسخ میدهیم.این سوالات به طور غریبی توسط علم ترد شده اند و پرل میخواد این غفلت علم رو جبران کنه.
اما صبر کنید مگه علم دقیقا در مورد پیدا کردن روابط علت و معلول نیست؟
پاسخ پرل به این سوال اینگونه است: دقیقا! اما شما نمیتوانید چنین چیزی را در معادلات علمی بیابید. زبان جبر متقارن هست به این معنی که اگر X ما رو به Y برسونه ، از Y نیز میتونیم به X برسیم.پرل در مورد روابط جبری (قطعی) صحبت میکنه، در ریاضی هیچ راهی وجود نداره که یک اثبات ساده نوشت که طوفان باعث پایین اومدن دما سنج میشه و نه برعکس.یا مثلا تئوری آشوب رو در نظر بگیرید، بخشی از این تئوری میگه که پروانه ای در آن سوی زمین پر میزند و باعث بوجود آمدن طوفان در سوی دیگر زمین میشود، حرف های قشنگی هست اما تا به حال چند طوفان رو تونستیم با این روش پیش بینی کنیم؟ بخشی کوتاهی از لکچر منطق ریاضی ، برگرفته شده از فیلم جنایات آکسفورد که به نظرم جالب و مرتبط با بحث ما بود رو با ترجمه گذاشتم، قبل از ادامه دادن مطلب،پیشنهاد میکنم نیگاه کنید:
ریاضی دانان هنوز زبان غیر متقارنی رو برای شرح چنین رویداد هایی بوجود نیاوردند که بگه: اگه X علت رخ دادن Y هست، به این معنی نیست که Y علت رخ دادن X است . اکثر مقالات مرتبط با یادگیری ماشینی که امروزه منتشر میشه به تشخیص یا بازشناسایی اختصاص داره به عنوان مثال برچسب گذاری یک شئی به عنوان گربه یا ببر، اونها فقط میخوان اشیاء رو تشخیص بدهند و پیش بینی کنند. اما همه اینها به سختی ذره ای از خروار هوش انسانیست.

شاید گفتن این جمله که “همه پیشرفت های اخیر یادگیری عمیق، فقط برارزش کردن یک منحنی بر روی داده ها هست” یک توهین بزرگ باشد اما اگر ما میخواهیم ماشین هایی داشته باشیم که بتوانند در مورد مداخله (“مثال : چی میشه اگه سیگار رو ممنوع کنیم؟”) و درون نگری (“مثال:چی میشد اگه مدرسه رو تموم کرده بودم؟”) استدلال کنند،بایستی مدل هایی سببی (عِلی) بوجود بیاریم.همبستگی (استدلال تداعی گرا) کافی نیست و این یک حقیقت ریاضی ست نه یک نظر.
تا کنون محققین این حوزه به این نتیجه رسیدن که بسیار از مسائل رو میشه با همین برارزش کردن حل کرد، اما نقشه راه آینده چیست؟ گام بعدی اونها چه خواهد بود؟ آیا با این روش میتوان ربات هایی ساخت که توانند مرزهایی دانش را بشکافند و به سوالات علمی حل نشده پاسخ دهند؟ این گام بعدی خواهد بود. ما همچنین خواستار یک ارتباط معنادار با ماشین ها هستیم و منظور من از معنادار ارتباطی ست که با درک مستقیم ما برابری میکنه و نه تبلیغات غلو آمیزی مثل این مورد :” فیس بوک بعد از اینکه ربات های سخنگوش زبانی جدید رو برای ارتباطات کلامی خودشون ساختند،از کار انداخت “ . اگه ربات ها رو از این مهارت (قدرت درک علت و معلول) محروم کنیم ،هیچگاه ربات هایی نخواهیم داشت که بتوانند به صورت معنادار با ما ارتباط برقرار کنند.این ربات ها هیچ گاه نخواهند توانست جملاتی مثل “باید بهتر انجامش میدادم” را بگویند، و ما یک کانال مهم از ارتباطات رو از دست میدیم.
ما بایستی ربات ها رو به یک مدل از محیط مجهز کنیم،اگر یک ربات هیچ مدلی از واقعیت نداشته باشه، نباید انتظار داشت که بتونه به صورت هوشمند رفتار کنه. اولین گام ، گامی که “شاید” در 10 سال اینده رخ خواهد داد اینه که ، مدل های مفهومی از واقعیت توسط انسانها برنامه نویسی خواهند شد. گام بعدی ماشین هایی خواهند بود که چنین مدل هایی رو توسط خودشون ایجاد ، و اونها رو براساس شواهد تجربیشون اصلاح و وارسی میکنند.این دقیقا چیزی است که برای علم اتفاق افتاد، ما با نظریه زمین مرکزی شروع کردیم و به نظریه خورشید مرکزی رسیدیم. روبات ها هم خواهند توانست با یکدیگر ارتباط برقرار کنند و این جهان سراسر از مدل های استعاری را محسور خواهند کرد.
در حال حاضر محققین جامعه هوش مصنوعی به دو دسته تقسیم شده اند ، اونهایی که سرمست موفقیت های یادگیری ماشین و یادگیری عمیق هستند. به اعتقاد من این گروه هستند که رویداد های علمی مثل NIPS2018 رو تبدیل به مارکت کردند! این کنفرانس در حالی در دسامبر امسال در شهر مونترآل برگزار میشه که تمامی بلیط ها در یکی دو روز گذشته زیر 12 دقیقه به فروش رسید و محققین این شاخه از علم را به بهت و حیرت فرو میبرد و از طرفی، تاسف برانگیز است.این کنفرانس یکی از بزرگترین رویدادهای هوش مصنوعی با حضور شرکت های گوگل،فیسبوک، مایکروسافت و DeepMind است. این کنفرانس از سال 1987 شروع شد و مترکز اصلی اون بر روی پیشرفت های یادگیری ماشین و علم اعصاب محاسباتی است.اما این کنفرانس در سال های اخیر که هوش مصنوعی به یک تکنولوژی “بزرگ” تبدیل شده ، محبوبیت خاصی رو بدست آورده.
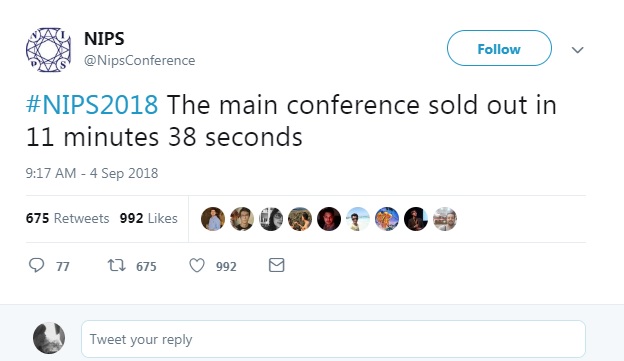
کاربران توییتر نیز به این اتفاق واکنش نشان دادند و اعلام کردند که کنفرانس های ضد NIPS رو برگزار خواهند کرد.
در این میان Ben Hammer (مدیر ارشد فن آوری Kaggle) به نقد از این کنفرانس میپردازه و مینویسه در حال حاضر خرید بلیط یه کنفرانس یادگیری ماشین سخت تر از خرید یه کنفرانس تیلور سوئیفت یا یک نمایش همیلتون (موزیکال) هست!
واکنش Nal Kalchbrenner محقق گوگل برین
حدود 2500 بلیط فروخته شد، این در حالیست که بین 6 تا 8 هزار بلیط برای نویسندگان مقالات دانشگاهی که در کنفرانس ارایه می شوند، رزرو شده است.یکی از صحنه های اندوه ناک NIPS 2017 تصویر زیر بود که نظر منو به خودش جلب کرد. تصویر پرل که تنها مانده است!

تصویر زیر نتیجه ارایه پرل بود که به نظر من حق کاملا با ایشان است.

جان کلام پرل اینه : هوش مصنوعی در سطح انسانی نمیتواد از ماشین هایی که به صورت “کور کورانه” یاد میگیرند پدید بیاد، اینگونه تحقیقات ، محدودیت های ذاتی بر روی کارهای شناختی که ماشین ها “میتوانند انجام بدهند”، تحمیل میکند. این روزها دادگان(Data) حکمرانان مدل ها هستند بدین معنی با کوچکترین تغییرات مدل ها در هم می شکنند.
برگردیم به ادامه بحث . به گروه اول پرداختیم ، این افراد میخوان به برازش کردن منحنی ادامه بدن ، دسته دوم افرادی هستند که خارج از یادگیری آماری کارهایی انجام داده اند. این افراد منظور من را متوجه میشوند. در چند ماه اخیر مقالات جالبی در زمینه محدودیت های یادگیری ماشین منتشر شده، به عنوان مثال:
Relational inductive biases, deep learning, and graph networks
Relational recurrent neural networks
Relational Deep Reinforcement Learning
منابع:
Review: ‘The Book of Why’ Examines the Science of Cause and Effect
GETTING FROM DUMB TO INTELLIGENT AI
‘Teachers, don’t fall for AI. It’s just spin’
NIPS 2013 Workshop on Causality
如何看待NIPS2017图灵奖得主贝叶斯网络之父Judea Pearl讲座无人问津?
图灵奖得主Judea Pearl:机器学习无法成为强AI基础,突破口在“因果革命”
AI Researchers Left Disappointed As NIPS Sells Out In Under 12 Minutes